我想问一下,在运行了我的Hadoop MapReduce应用程序之后,如何获取该应用程序的总内存和CPU使用情况。我在日志和资源管理器网页上看到过,但是没有理解清楚。
这是否可能?我可以按作业执行或按应用程序获取它,还可以按节点使用或总使用情况获取吗?
非常感谢...
这是否可能?我可以按作业执行或按应用程序获取它,还可以按节点使用或总使用情况获取吗?
非常感谢...
是的,您可以很好地检查应用程序的总内存和CPU使用情况。
您可以使用作业跟踪器UI,在已完成页面上点击计数器链接,可能会得到以下典型视图。内存和CPU计数器已突出显示。
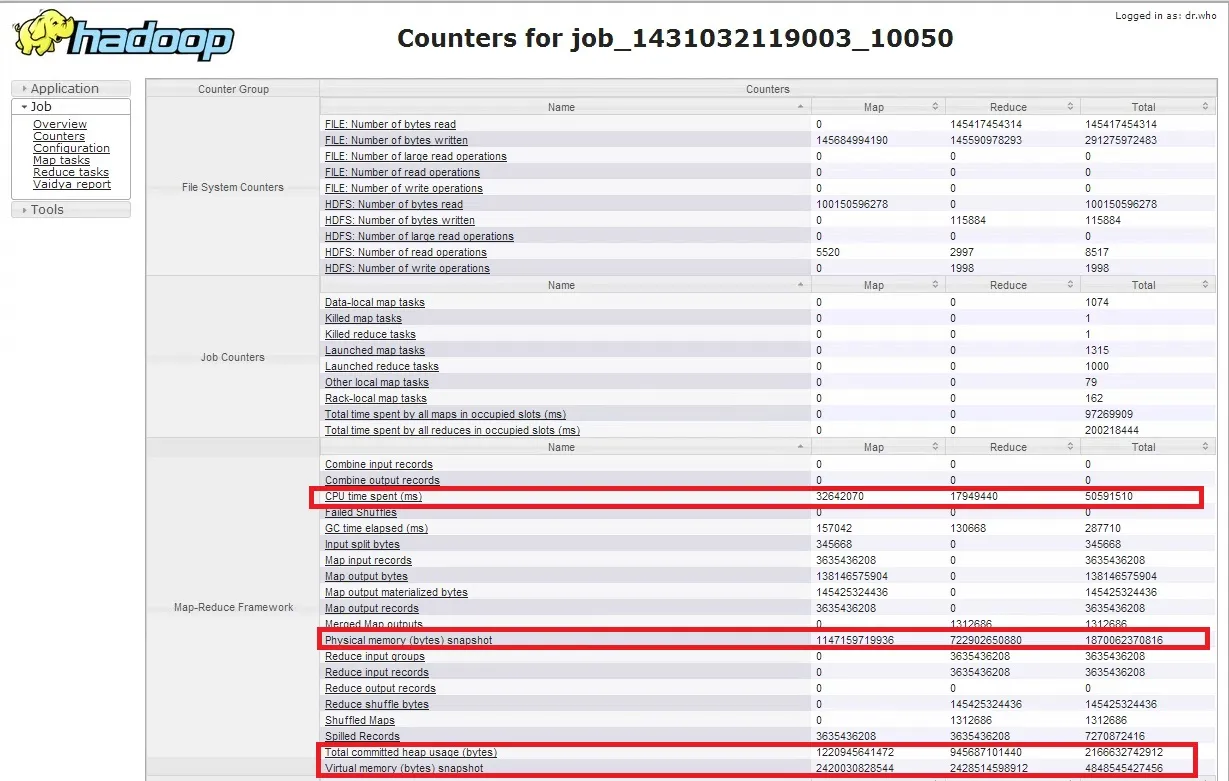
点击突出显示的链接将向您显示作业中每个任务(Map/Reduce)的消耗。
要从命令行查看这些消耗计数器的值,您可以使用
hadoop job -counter <job-id> org.apache.hadoop.mapreduce.TaskCounter CPU_MILLISECONDS 用于CPU使用情况
hadoop job -counter <job-id> org.apache.hadoop.mapreduce.TaskCounter PHYSICAL_MEMORY_BYTES 用于内存使用情况
hadoop job -counter <job-id> org.apache.hadoop.mapreduce.TaskCounter CPU_MILLISECONDS查询CPU使用情况,使用hadoop job -counter <job-id> org.apache.hadoop.mapreduce.TaskCounter PHYSICAL_MEMORY_BYTES查询内存使用情况。 - suresiva