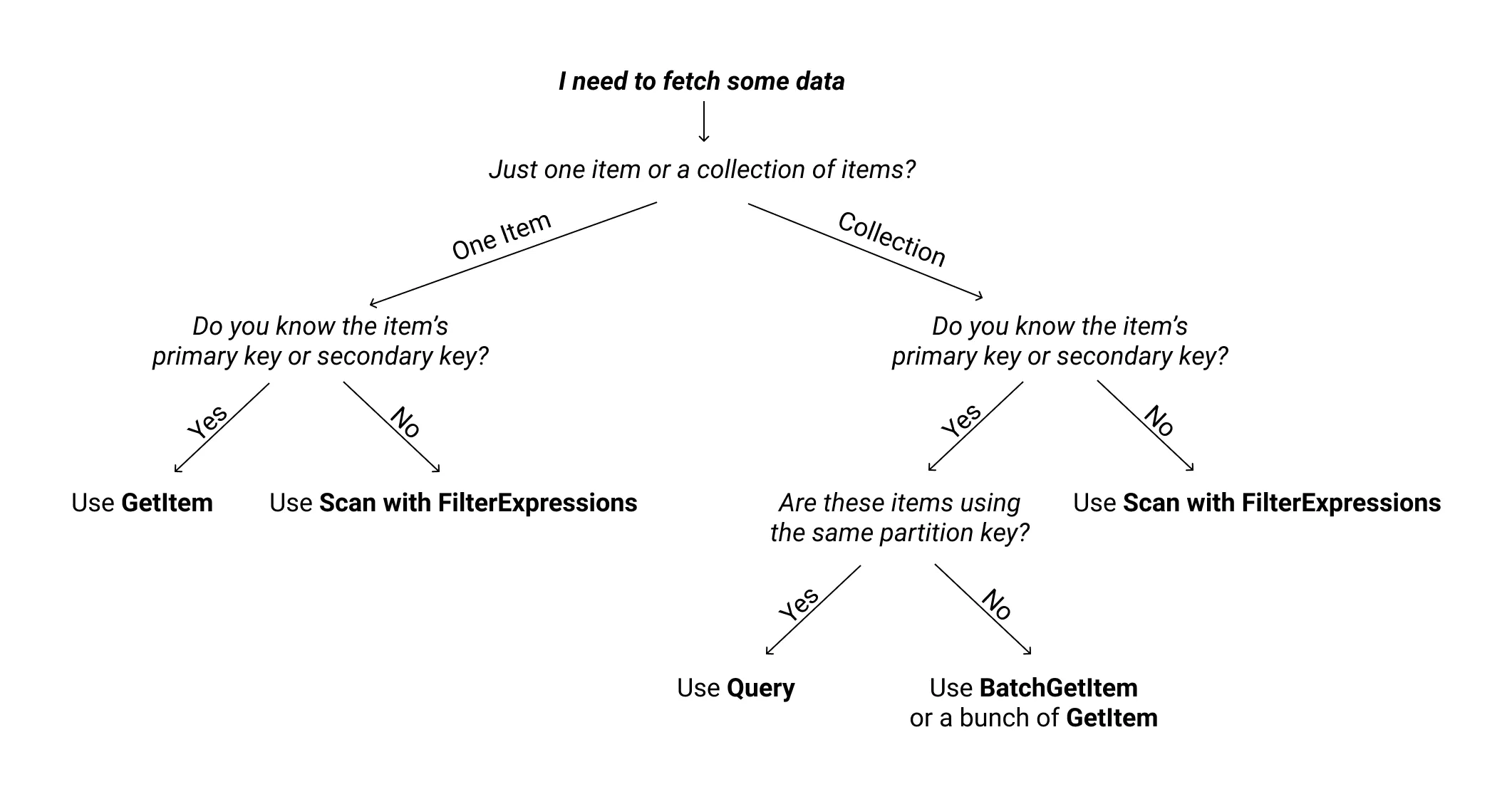
如果我根据索引的哈希键检索表中的单个项目,那么在使用
query() 或者 getItem() 时是否存在性能差异?query() 或者 getItem() 时是否存在性能差异?getItem 将更快
getItem 通过哈希和范围键检索是一种完美的匹配,因此检索所需时间(性能)受到内部哈希和分片的限制。
查询结果在搜索“所有”范围键时添加了计算工作,因此被认为比较慢。
编辑:为了快速比较,附上来自此博客文章的以下图片。
在亚马逊的DynamoDB中,无论使用何种访问方式,您都可以保证性能(需要支付费用)。
正如Chen Harel所建议的那样,DynamoDB服务器本身可能会有几毫秒的差异,但由于HTTP请求的往返时间(RTT),这些差异微不足道。
尽管如此,当您拥有足够的信息时,最好发出GET而不是QUERY请求,这是一个好习惯。
这两者之间没有性能差异。两个查询中的哈希计算都是逐个完成的。 后者,即getItem仅作为类比JPA repository / spring findOne / findById,并使Spring Bean wiring / Hibernate配置更容易。