我正在开发一个C++应用程序,该程序会无限运行,随着时间的推移分配和释放数百万个字符串(char*)。内存使用是该程序的重要考虑因素。这导致内存使用随着时间的推移越来越高。我认为问题出在堆碎片上。我真的需要找到一个解决方案。
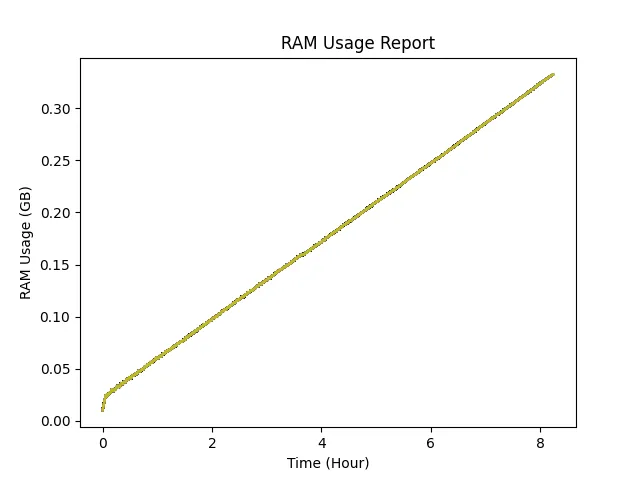
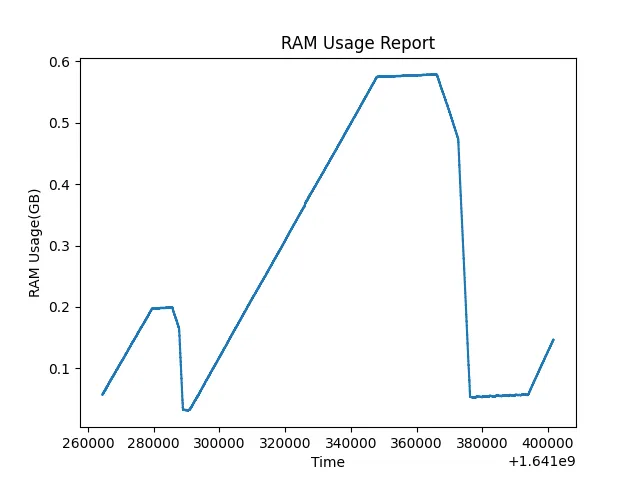
malloc_trim(0),似乎应用程序最终可以将未使用的内存返回给操作系统,并且它几乎降到了零(当前我的程序实际数据大小)。这意味着问题不是内存泄漏。但我不能依赖这种行为,我的程序分配和释放模式是随机的,如果它永远不释放内存会怎么样?
- 我在标题中说过,内存池对这个项目来说不是一个好主意。当然我没有绝对的知识。但我分配的字符串可以是30-4000字节之间的任何内容。这使得许多优化和聪明的想法变得更加困难。内存池就是其中之一。
- 我正在使用
GCC 11 / G++ 11编译器。如果一些旧版本有糟糕的分配器,那么我不应该有这个问题。 - 我如何获得内存使用情况?使用Python的
psutil模块。proc.memory_full_info()[0],它给了我RSS。 - 当然,你不知道我的程序细节。如果确实是由于堆碎片导致的问题,这仍然是一个有效的问题。嗯,我能说的是,我会及时更新关于程序中发生了多少次分配和释放的信息。我知道程序中每个容器的元素计数。但如果你仍然有关于问题原因的一些想法,我愿意听取建议。
- 我不能只为所有字符串分配4096个字节,以便更容易地进行优化。这与我的尝试相反。
我的问题是,当一个应用程序在不同大小的内存分配和释放操作中需要进行数百万次操作时,程序员(或我)该怎么做才能更高效地使用内存池?我无法改变程序所做的事情,只能改变实现细节。
Bounty Edit:当尝试利用内存池时,是否可以制作多个内存池,以至于每个字节计数都有一个对应的池呢?例如,我的字符串长度可能在30-4000个字节之间。那么,每个可能的分配大小都可以制作4000 - 30 + 1,3971个内存池。所有内存池都可以从小开始(因此不会损失太多内存),然后在性能和内存之间取得平衡。我并不是要利用内存池提前保留大空间。我只是想有效地重复使用已释放的空间,因为会频繁进行内存分配和释放。
char数组和new/delete?你尝试过像 valgrind 这样的工具来获取更多信息吗? - MatG