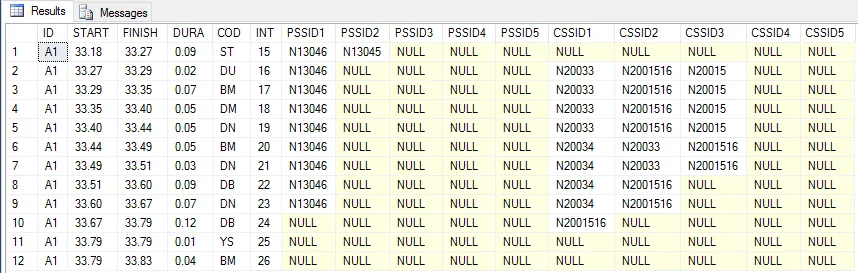
我正在努力创建一个查询,可以将列中的多个值拆分成多个列,以帮助“去重”数据集。
如下数据最好解释,但基本上您会注意到一个间隔字段,它是ID、START、FINISH、DURATION、COD列中的密集等级。由于多个重叠的PSSID和CSSID值,这些间隔是重复的。我想知道是否有一种好的方法来动态地将重叠的PSSID和CSSID字段拆分成多个列...! 那么我实际上是什么意思...
示例数据:
ID START FINISH DURA COD INT PSSID CSSID
A1 33.18 33.27 0.09 ST 15 N13045 NULL
A1 33.18 33.27 0.09 ST 15 N13046 NULL
A1 33.27 33.285 0.015 DU 16 N13046 NULL
A1 33.27 33.285 0.015 DU 16 NULL N20015
A1 33.27 33.285 0.015 DU 16 NULL N2001516
A1 33.27 33.285 0.015 DU 16 NULL N20033
A1 33.285 33.35 0.065 BM 17 N13046 NULL
A1 33.285 33.35 0.065 BM 17 NULL N20015
A1 33.285 33.35 0.065 BM 17 NULL N2001516
A1 33.285 33.35 0.065 BM 17 NULL N20033
A1 33.35 33.395 0.045 DM 18 N13046 NULL
A1 33.35 33.395 0.045 DM 18 NULL N20015
A1 33.35 33.395 0.045 DM 18 NULL N2001516
A1 33.35 33.395 0.045 DM 18 NULL N20033
A1 33.395 33.44 0.045 DN 19 N13046 NULL
A1 33.395 33.44 0.045 DN 19 NULL N20015
A1 33.395 33.44 0.045 DN 19 NULL N2001516
A1 33.395 33.44 0.045 DN 19 NULL N20033
A1 33.44 33.485 0.045 BM 20 N13046 NULL
A1 33.44 33.485 0.045 BM 20 NULL N2001516
A1 33.44 33.485 0.045 BM 20 NULL N20033
A1 33.44 33.485 0.045 BM 20 NULL N20034
A1 33.485 33.51 0.025 DN 21 N13046 NULL
A1 33.485 33.51 0.025 DN 21 NULL N2001516
A1 33.485 33.51 0.025 DN 21 NULL N20033
A1 33.485 33.51 0.025 DN 21 NULL N20034
A1 33.51 33.595 0.085 DB 22 N13046 NULL
A1 33.51 33.595 0.085 DB 22 NULL N2001516
A1 33.51 33.595 0.085 DB 22 NULL N20034
A1 33.595 33.665 0.07 DN 23 N13046 NULL
A1 33.595 33.665 0.07 DN 23 NULL N2001516
A1 33.595 33.665 0.07 DN 23 NULL N20034
A1 33.665 33.785 0.12 DB 24 NULL N2001516
A1 33.785 33.79 0.005 YS 25 NULL NULL
A1 33.79 33.83 0.04 BM 26 NULL NULL
期望输出:
ID START FINISH DURA COD INT PSSID1 PSSID2 CSSID1 CSSID2 CSSID3
A1 33.18 33.27 0.09 ST 15 N13046 N13045 NULL NULL NULL
A1 33.27 33.285 0.015 DU 16 N13046 NULL N20015 N2001516 N20033
A1 33.285 33.35 0.065 BM 17 N13046 NULL N20015 N2001516 N20033
A1 33.35 33.395 0.045 DM 18 N13046 NULL N20015 N2001516 N20033
A1 33.395 33.44 0.045 DN 19 N13046 NULL N20015 N2001516 N20033
A1 33.44 33.485 0.045 BM 20 N13046 NULL N20034 N2001516 N20033
A1 33.485 33.51 0.025 DN 21 N13046 NULL N20034 N2001516 N20033
A1 33.51 33.595 0.085 DB 22 N13046 NULL N20034 N2001516 NULL
A1 33.595 33.665 0.07 DN 23 N13046 NULL N20034 N2001516 NULL
A1 33.665 33.785 0.12 DB 24 NULL NULL NULL N2001516 NULL
A1 33.785 33.79 0.005 YS 25 NULL NULL NULL NULL NULL
A1 33.79 33.83 0.04 BM 26 NULL NULL NULL NULL NULL
更糟糕的是,这只是一小部分示例数据,对于给定时间间隔可能有超过三个PSSID、CSSID字段(尽管它应该有上限为5)。因此,查询需要是动态的以允许这种情况。
我正在使用SQL Server 2012。上述数据的架构如下所示:
CREATE TABLE #SampleData
([ID] varchar(2), [START] decimal(9,2), [FINISH] decimal(9,2), [DURA] decimal(9,2), [COD] varchar(2), [INT] int, [PSSID] varchar(6), [CSSID] varchar(8))
;
INSERT INTO #SampleData
([ID], [START], [FINISH], [DURA], [COD], [INT], [PSSID], [CSSID])
VALUES
('A1', 33.18, 33.27, 0.09, 'ST', 15, 'N13045', NULL),
('A1', 33.18, 33.27, 0.09, 'ST', 15, 'N13046', NULL),
('A1', 33.27, 33.285, 0.015, 'DU', 16, 'N13046', NULL),
('A1', 33.27, 33.285, 0.015, 'DU', 16, NULL, 'N20015'),
('A1', 33.27, 33.285, 0.015, 'DU', 16, NULL, 'N2001516'),
('A1', 33.27, 33.285, 0.015, 'DU', 16, NULL, 'N20033'),
('A1', 33.285, 33.35, 0.065, 'BM', 17, 'N13046', NULL),
('A1', 33.285, 33.35, 0.065, 'BM', 17, NULL, 'N20015'),
('A1', 33.285, 33.35, 0.065, 'BM', 17, NULL, 'N2001516'),
('A1', 33.285, 33.35, 0.065, 'BM', 17, NULL, 'N20033'),
('A1', 33.35, 33.395, 0.045, 'DM', 18, 'N13046', NULL),
('A1', 33.35, 33.395, 0.045, 'DM', 18, NULL, 'N20015'),
('A1', 33.35, 33.395, 0.045, 'DM', 18, NULL, 'N2001516'),
('A1', 33.35, 33.395, 0.045, 'DM', 18, NULL, 'N20033'),
('A1', 33.395, 33.44, 0.045, 'DN', 19, 'N13046', NULL),
('A1', 33.395, 33.44, 0.045, 'DN', 19, NULL, 'N20015'),
('A1', 33.395, 33.44, 0.045, 'DN', 19, NULL, 'N2001516'),
('A1', 33.395, 33.44, 0.045, 'DN', 19, NULL, 'N20033'),
('A1', 33.44, 33.485, 0.045, 'BM', 20, 'N13046', NULL),
('A1', 33.44, 33.485, 0.045, 'BM', 20, NULL, 'N2001516'),
('A1', 33.44, 33.485, 0.045, 'BM', 20, NULL, 'N20033'),
('A1', 33.44, 33.485, 0.045, 'BM', 20, NULL, 'N20034'),
('A1', 33.485, 33.51, 0.025, 'DN', 21, 'N13046', NULL),
('A1', 33.485, 33.51, 0.025, 'DN', 21, NULL, 'N2001516'),
('A1', 33.485, 33.51, 0.025, 'DN', 21, NULL, 'N20033'),
('A1', 33.485, 33.51, 0.025, 'DN', 21, NULL, 'N20034'),
('A1', 33.51, 33.595, 0.085, 'DB', 22, 'N13046', NULL),
('A1', 33.51, 33.595, 0.085, 'DB', 22, NULL, 'N2001516'),
('A1', 33.51, 33.595, 0.085, 'DB', 22, NULL, 'N20034'),
('A1', 33.595, 33.665, 0.07, 'DN', 23, 'N13046', NULL),
('A1', 33.595, 33.665, 0.07, 'DN', 23, NULL, 'N2001516'),
('A1', 33.595, 33.665, 0.07, 'DN', 23, NULL, 'N20034'),
('A1', 33.665, 33.785, 0.12, 'DB', 24, NULL, 'N2001516'),
('A1', 33.785, 33.79, 0.005, 'YS', 25, NULL, NULL),
('A1', 33.79, 33.83, 0.04, 'BM', 26, NULL, NULL)
;
感谢您的帮助!