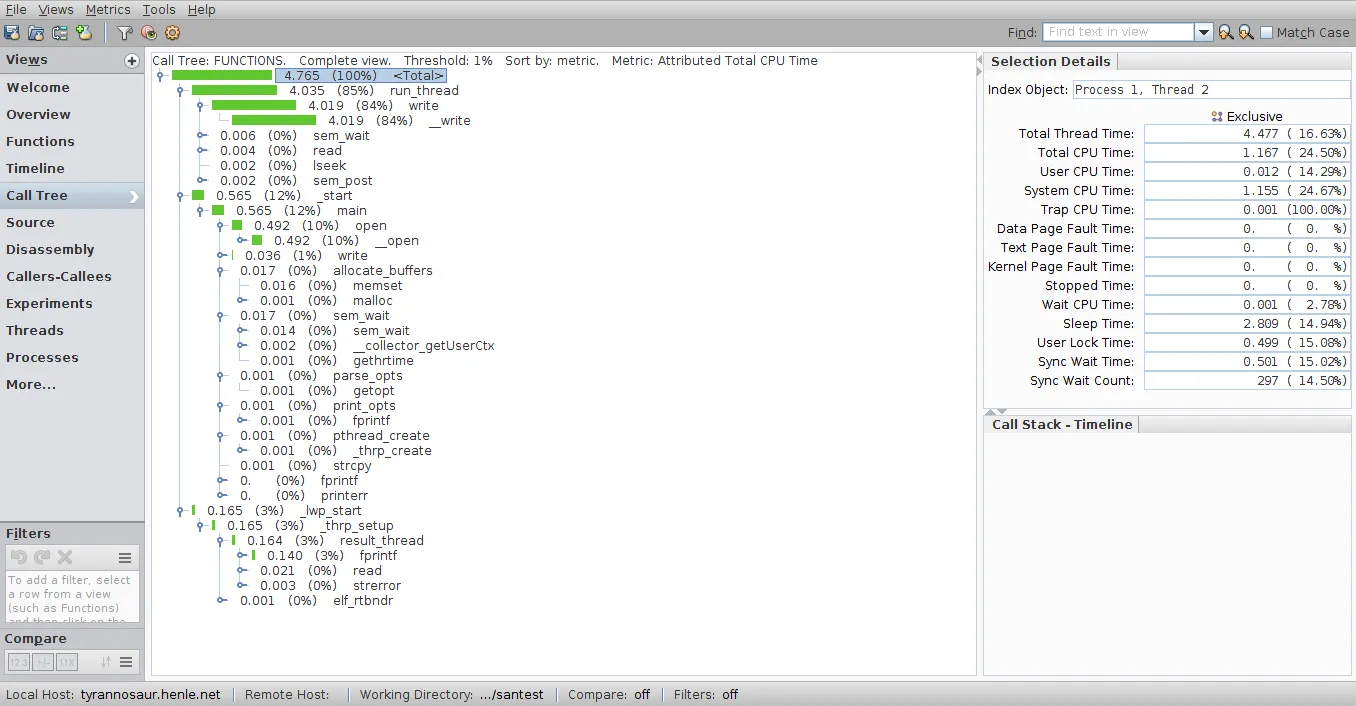
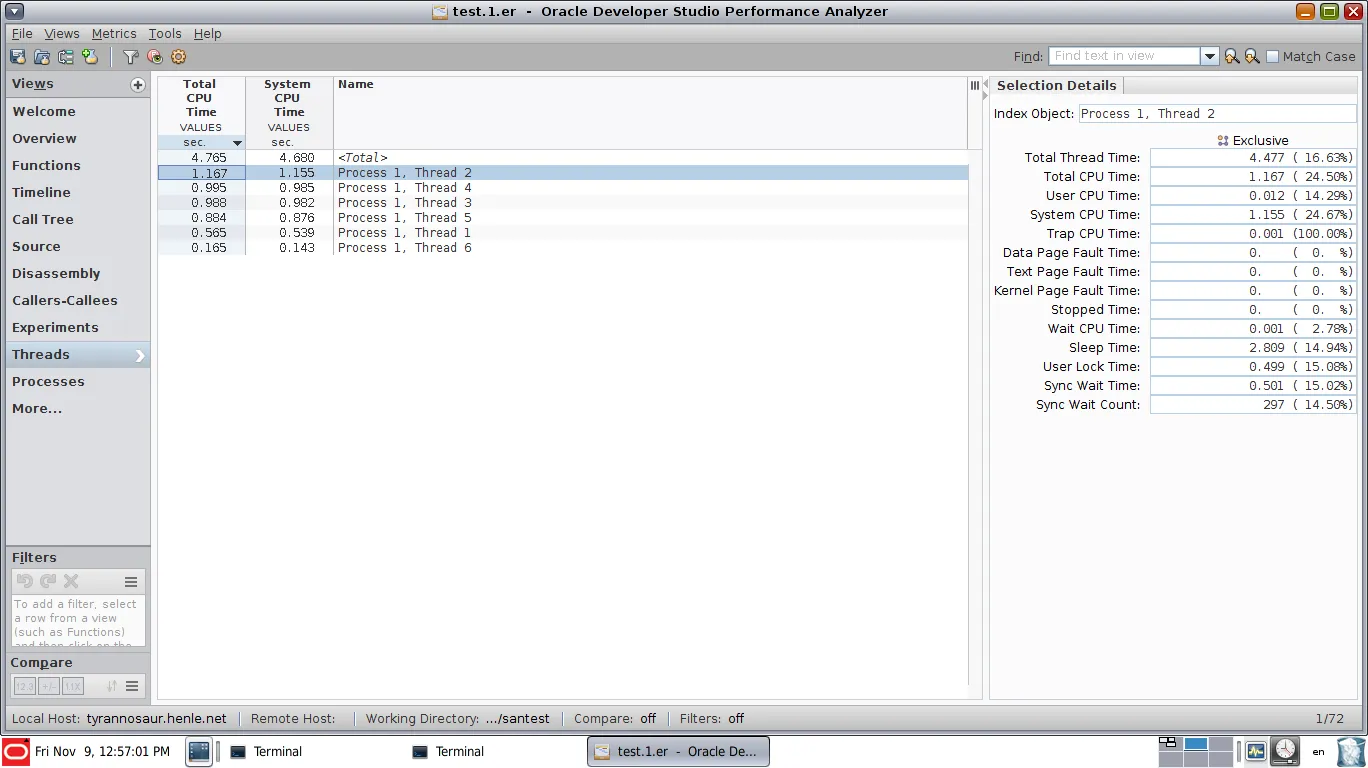
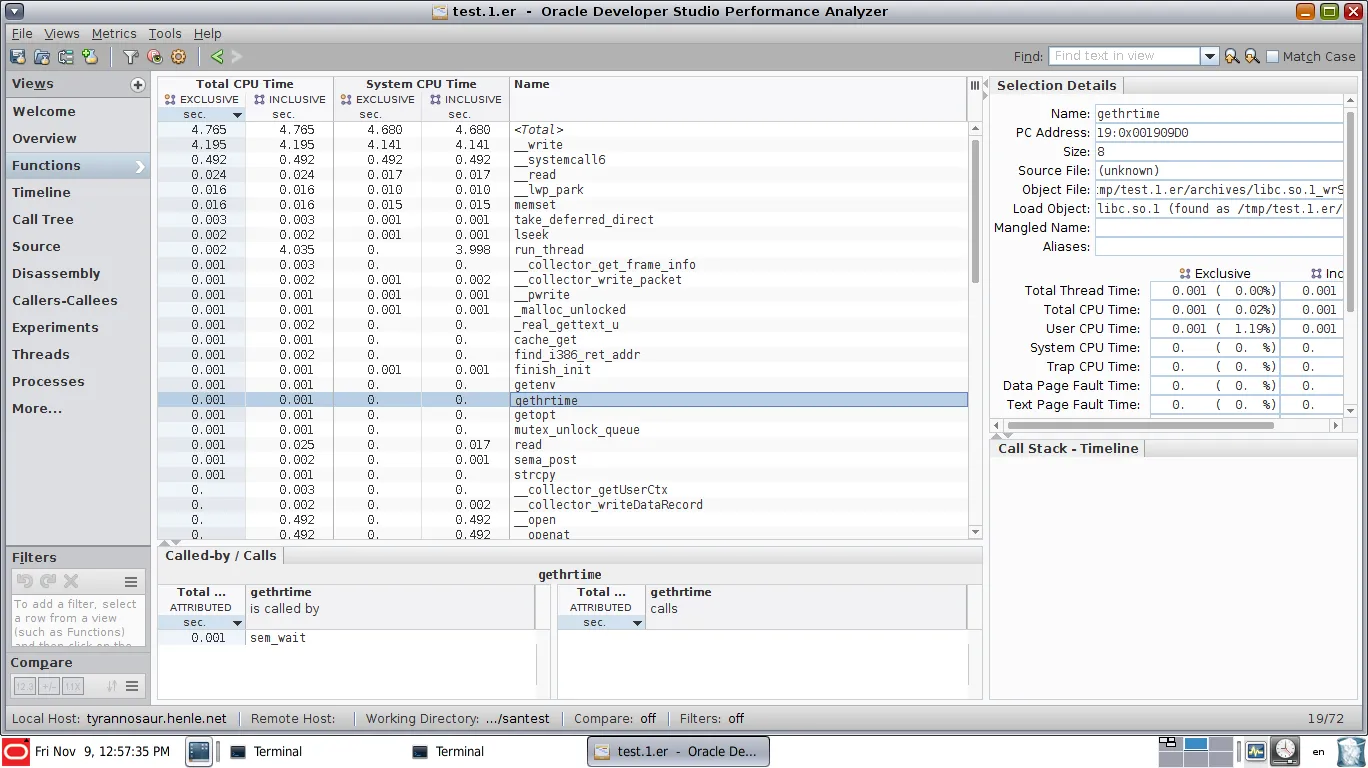
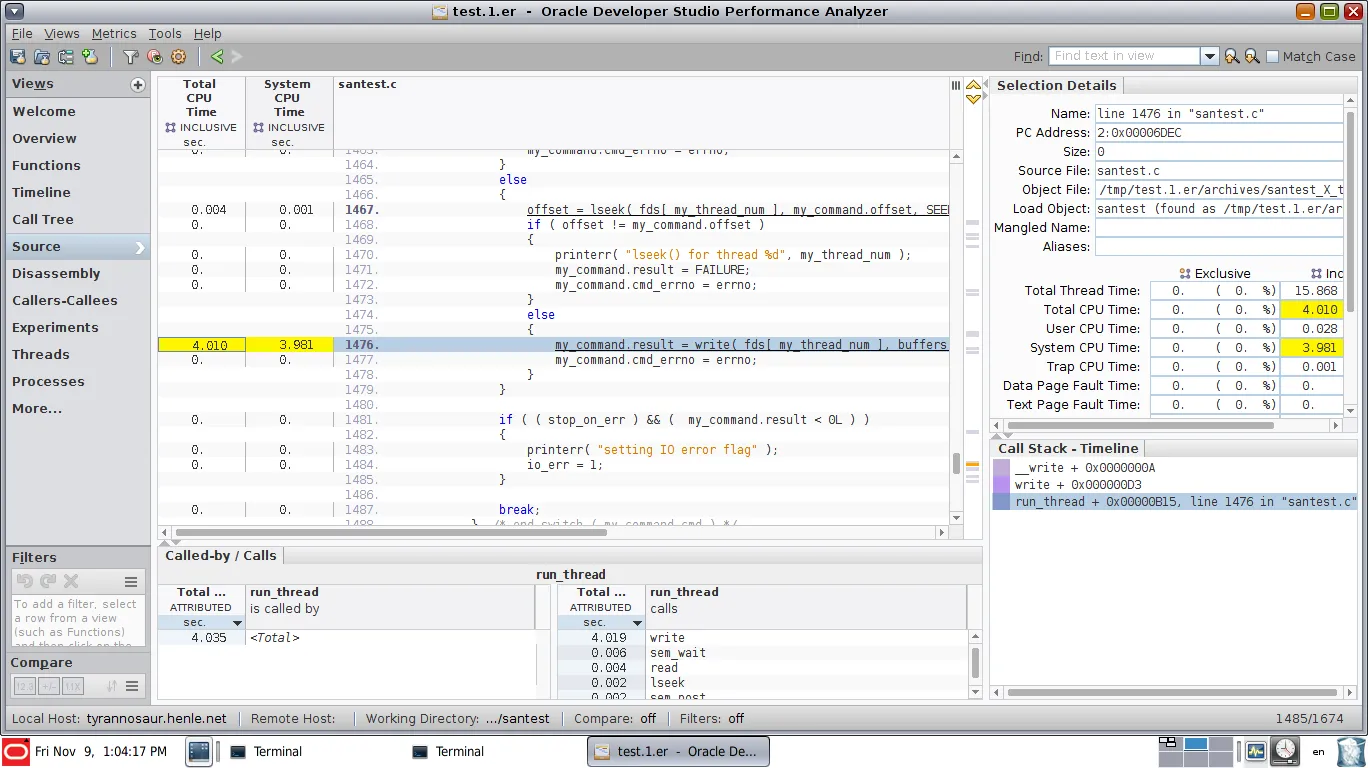
Linux性能工具非常适合找到CPU周期热点并优化这些热点。但一旦某些部分被并行化,就很难发现顺序执行的部分,因为它们占据了相当大的墙上时间,但不一定需要很多CPU周期(并行部分已经在消耗这些周期)。
为避免XY问题:我的基本动机是找到多线程代码中的顺序瓶颈。尽管由于阿姆达尔定律顺序执行的阶段占据了墙上的时间,但并行阶段可以轻松支配聚合CPU周期统计数据。
对于Java应用程序,使用visualvm或yourkit很容易实现线程利用率时间轴。
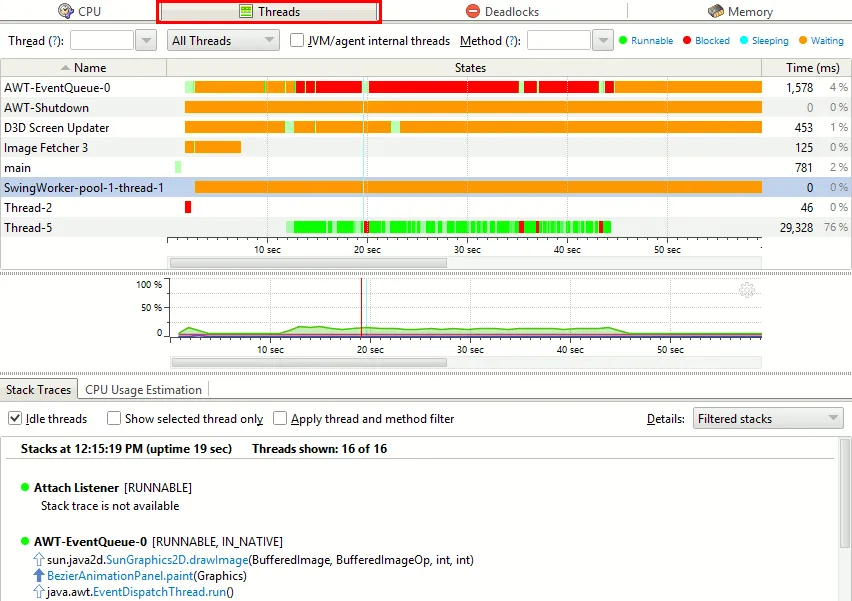
请注意,它显示所选时间范围或时间点的线程状态(可运行,等待,阻塞)和堆栈样本。
如何使用perf或其他Linux本机分析器实现类似的功能?它不必是GUI可视化,只要找到顺序瓶颈和与其关联的CPU样本即可。
另请参见更窄后续问题,重点关注perf。
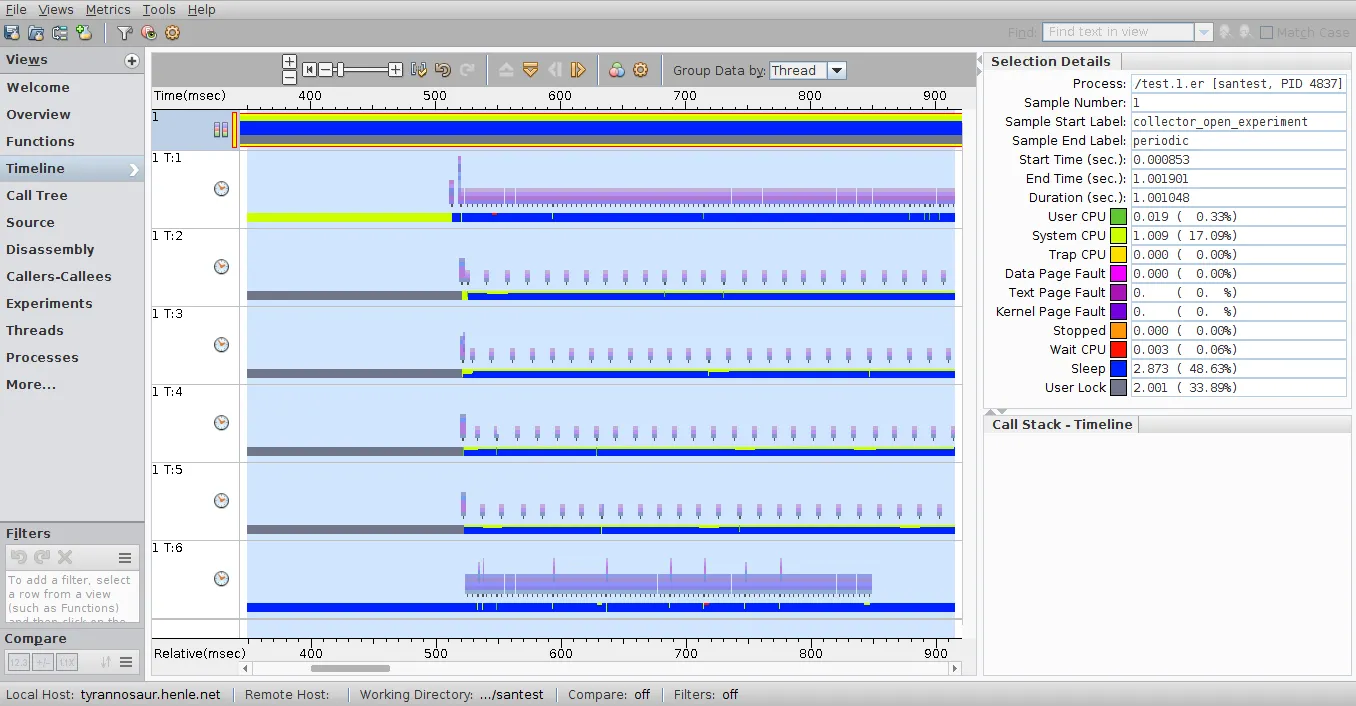
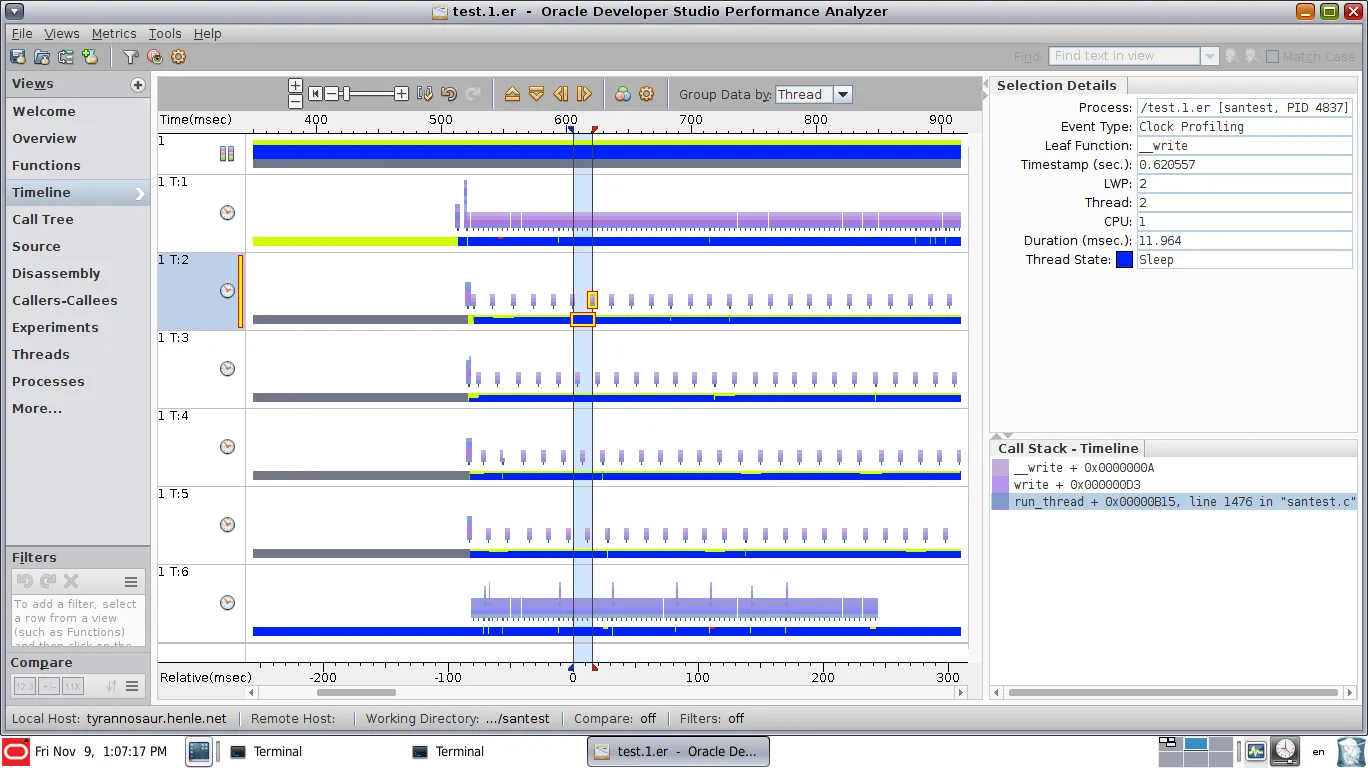
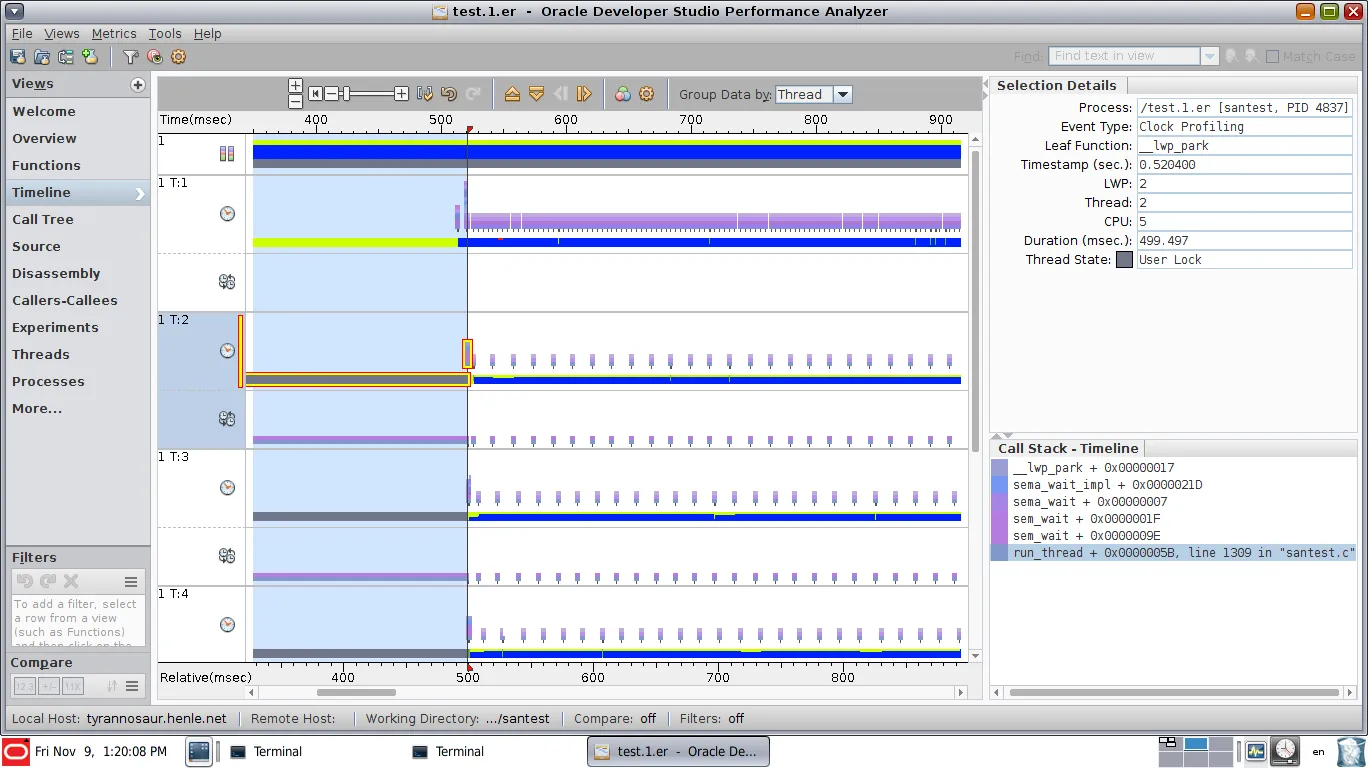

{kind=link}
perf report文本用户界面或选项来“聚焦”于某些线程:perf record -g -F 99 -s ./your_program; perf report -T或perf report -T --tid=$TID,其中 $TID 是一个线程的 pid 或逗号分隔列表。我没有测试 -s/-T 选项来拆分线程统计信息,但它们已经被记录在文档中:http://man7.org/linux/man-pages/man1/perf-record.1.html http://man7.org/linux/man-pages/man1/perf-report.1.html;per-thread 是默认模式:https://perf.wiki.kernel.org/index.php/Tutorial#Collecting_samples - osgx