使用AVX2可以进行4位数的加法/乘法,特别是如果您想在更大的向量上应用这些计算(例如超过128个元素)。但是,如果您只想添加4个数字,请使用直接标量代码。
我们已经对如何处理4位整数进行了广泛的研究,并最近开发了一个库来处理它
Clover:4位量化线性代数库(重点关注量化)。该代码也
可在GitHub上获得。
由于您提到的仅为
4位整数,我假设您指的是带符号整数(即二进制补码),并根据此回答。请注意,处理无符号整数实际上要简单得多。
我还假设您想要取出包含n个4位整数的矢量int8_t v [n / 2],并生成具有n / 4个4位整数的int8_t v_sum [n / 4]。下面是所有与描述相关的代码
作为gist可用。
打包/解包
显然,AVX2不提供任何指令来执行4位整数的加法/乘法,因此必须采用给定的8位或16位指令。处理4位算术的第一步是设计方法,将4位半字节放入更大的8、16或32位块中。
为了清晰起见,假设您想要从存储多个4位有符号值的32位块中解包给定的半字节到相应的32位整数(如下图)。这可以通过两次位移来完成:
- 逻辑左移用于将半字节向左移位,使其占据32位实体的高4位。
- 算术右移用于将半字节向右移动到32位实体的最低4位。
算术右移具有符号扩展功能,使用半字节的符号位填充高28位。得到一个32位整数,其值与二进制补码的4位值相同。
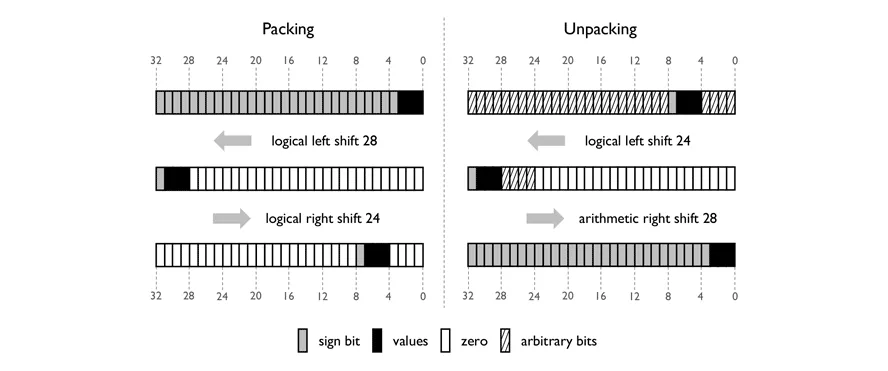
打包的目标(上图左侧)是恢复解包操作。可以使用两个位移来将32位整数的最低4位放置在32位实体中的任何位置。
1. 逻辑左移用于将半字节移位,以使其占据32位实体的最高4位。
2. 逻辑右移用于将半字节移动到32位实体中的某个位置。
第一个将半字节低于位设置为零,第二个将半字节高于位设置为零。然后可以使用按位OR操作将最多8个半字节存储在32位实体中。
如何在实践中应用呢?
假设您在8个AVX寄存器__m256i q_1、q_2、q_3、q_4、q_5、q_6、q_7、q_8中存储了64个32位整数值。假设每个值都在[-8, 7]范围内。如果您想将它们打包成一个64 x 4位值的单个AVX寄存器,则可以按以下方式操作:
//
// Transpose the 8x8 registers
//
_mm256_transpose8_epi32(q_1, q_2, q_3, q_4, q_5, q_6, q_7, q_8)
//
// Shift values left
//
q_1 = _mm256_slli_epi32(q_1, 28)
q_2 = _mm256_slli_epi32(q_2, 28)
q_3 = _mm256_slli_epi32(q_3, 28)
q_4 = _mm256_slli_epi32(q_4, 28)
q_5 = _mm256_slli_epi32(q_5, 28)
q_6 = _mm256_slli_epi32(q_6, 28)
q_7 = _mm256_slli_epi32(q_7, 28)
q_8 = _mm256_slli_epi32(q_8, 28)
//
// Shift values right (zero-extend)
//
q_1 = _mm256_srli_epi32(q_1, 7 * 4)
q_2 = _mm256_srli_epi32(q_2, 6 * 4)
q_3 = _mm256_srli_epi32(q_3, 5 * 4)
q_4 = _mm256_srli_epi32(q_4, 4 * 4)
q_5 = _mm256_srli_epi32(q_5, 3 * 4)
q_6 = _mm256_srli_epi32(q_6, 2 * 4)
q_7 = _mm256_srli_epi32(q_7, 1 * 4)
q_8 = _mm256_srli_epi32(q_8, 0 * 4)
//
// Pack together
//
__m256i t1 = _mm256_or_si256(q_1, q_2)
__m256i t2 = _mm256_or_si256(q_3, q_4)
__m256i t3 = _mm256_or_si256(q_5, q_6)
__m256i t4 = _mm256_or_si256(q_7, q_8)
__m256i t5 = _mm256_or_si256(t1, t2)
__m256i t6 = _mm256_or_si256(t3, t4)
__m256i t7 = _mm256_or_si256(t5, t6)
移位通常需要一个吞吐周期和一个延迟周期,因此可以认为它们实际上相当便宜。如果您需要处理无符号4位值,则可以完全跳过左移操作。
要反转该过程,可以应用相同的方法。假设您已将64个4位值加载到单个AVX寄存器__m256i qu_64中。为了生成64个32位整数__m256i q_1, q_2, q_3, q_4, q_5, q_6, q_7, q_8,请执行以下操作:
//
// Shift values left
//
const __m256i qu_1 = _mm256_slli_epi32(qu_64, 4 * 7)
const __m256i qu_2 = _mm256_slli_epi32(qu_64, 4 * 6)
const __m256i qu_3 = _mm256_slli_epi32(qu_64, 4 * 5)
const __m256i qu_4 = _mm256_slli_epi32(qu_64, 4 * 4)
const __m256i qu_5 = _mm256_slli_epi32(qu_64, 4 * 3)
const __m256i qu_6 = _mm256_slli_epi32(qu_64, 4 * 2)
const __m256i qu_7 = _mm256_slli_epi32(qu_64, 4 * 1)
const __m256i qu_8 = _mm256_slli_epi32(qu_64, 4 * 0)
//
// Shift values right (sign-extent) and obtain 8x8
// 32-bit values
//
__m256i q_1 = _mm256_srai_epi32(qu_1, 28)
__m256i q_2 = _mm256_srai_epi32(qu_2, 28)
__m256i q_3 = _mm256_srai_epi32(qu_3, 28)
__m256i q_4 = _mm256_srai_epi32(qu_4, 28)
__m256i q_5 = _mm256_srai_epi32(qu_5, 28)
__m256i q_6 = _mm256_srai_epi32(qu_6, 28)
__m256i q_7 = _mm256_srai_epi32(qu_7, 28)
__m256i q_8 = _mm256_srai_epi32(qu_8, 28)
//
// Transpose the 8x8 values
//
_mm256_transpose8_epi32(q_1, q_2, q_3, q_4, q_5, q_6, q_7, q_8)
如果处理无符号的4位,右移(
_mm256_srai_epi32)可以完全跳过,而左移可以执行左逻辑移位(
_mm256_srli_epi32 )。请参见
gist here了解更多细节。
添加奇偶4位条目
假设您使用
AVX从向量加载:
const __m256i qv = _mm256_loadu_si256( ... )
现在,我们可以轻松地提取奇数部分和偶数部分。如果
AVX2中有8位移位操作,那么生活会变得容易得多,但是实际上没有,所以我们必须处理16位移位操作:
const __m256i hi_mask_08 = _mm256_set1_epi8(-16);
const __m256i qv_odd_dirty = _mm256_slli_epi16(qv, 4);
const __m256i qv_odd_shift = _mm256_and_si256(hi_mask_08, qv_odd_dirty);
const __m256i qv_evn_shift = _mm256_and_si256(hi_mask_08, qv);
此时,您已经将奇数和偶数的四位二进制数分别放入两个AVX寄存器中,它们的值在高4位中(即范围在[-8 * 2^4, 7 * 2^4]之间)。即使处理无符号的4位二进制数,该过程也是相同的。现在是将这些值相加的时候了。
const __m256i qv_sum_shift = _mm256_add_epi8(qv_odd_shift, qv_evn_shift);
这将适用于有符号和无符号,因为二进制加法使用二补数。但是,如果您想避免溢出或下溢,您也可以考虑饱和加法,它已经在AVX中得到支持(适用于有符号和无符号)。
__m256i _mm256_adds_epi8 (__m256i a, __m256i b)
__m256i _mm256_adds_epu8 (__m256i a, __m256i b)
qv_sum_shift 的范围将在 [-8 * 2^4, 7 * 2^4] 之间。为了设置正确的值,我们需要将其向后移位(请注意,如果 qv_sum 必须是无符号的,我们可以使用 _mm256_srli_epi16)。
const __m256i qv_sum = _mm256_srai_epi16(qv_sum_shift, 4);
总结已经完成。根据您的用例,这可能是程序的结尾,假设您想要生成8位内存块作为结果。但是让我们假设您想解决一个更难的问题。假设输出再次是4位元素的向量,并且与输入相同的内存布局。在这种情况下,我们需要将8位块打包成4位块。但是,问题在于我们将得到32个值而不是64个值(即向量大小的一半)。
从这一点出发,有两个选择。我们可以向前查看向量,处理128 x 4位值,以便我们生成64 x 4位值。或者我们回到SSE,处理32 x 4位值。无论哪种方式,将8位块打包成4位块的最快方法是使用
vpackuswb指令(对于
SSE,使用
packuswb)。
__m256i _mm256_packus_epi16 (__m256i a, __m256i b)
这条指令将从
a和
b中提取压缩的16位整数,使用无符号饱和转换为压缩的8位整数,并将结果存储在
dst中。这意味着我们需要交错奇数和偶数4位值,使它们驻留在16位内存块的8个低位中。我们可以按以下步骤进行:
const __m256i lo_mask_16 = _mm256_set1_epi16(0x0F)
const __m256i hi_mask_16 = _mm256_set1_epi16(0xF0)
const __m256i qv_sum_lo = _mm256_and_si256(lo_mask_16, qv_sum)
const __m256i qv_sum_hi_dirty = _mm256_srli_epi16(qv_sum_shift, 8)
const __m256i qv_sum_hi = _mm256_and_si256(hi_mask_16, qv_sum_hi_dirty)
const __m256i qv_sum_16 = _mm256_or_si256(qv_sum_lo, qv_sum_hi)
该过程对于有符号和无符号的4位值都是相同的。现在,
qv_sum_16包含两个连续的4位值,存储在16位内存块的低位中。假设我们从下一次迭代(称为
qv_sum_16_next)获得了
qv_sum_16,我们可以使用以下方式打包所有内容:
const __m256i qv_sum_pack = _mm256_packus_epi16(qv_sum_16, qv_sum_16_next);
const __m256i result = _mm256_permute4x64_epi64(qv_sum_pack, 0xD8);
另外,如果我们只想生成32个4位值,可以按照以下方式进行:
const __m128i lo = _mm256_extractf128_si256(qv_sum_16, 0)
const __m128i hi = _mm256_extractf128_si256(qv_sum_16, 1)
const __m256i result = _mm_packus_epi16(lo, hi)
将所有内容整合在一起
假设使用有符号的四位字节,并且向量大小为n,其中n大于128个元素且是128的倍数,我们可以执行奇偶加法,如下所示,产生n/2个元素:
void add_odd_even(uint64_t n, int8_t * v, int8_t * r)
{
//
// Make sure that the vector size that is a multiple of 128
//
assert(n % 128 == 0)
const uint64_t blocks = n / 64
//
// Define constants that will be used for masking operations
//
const __m256i hi_mask_08 = _mm256_set1_epi8(-16)
const __m256i lo_mask_16 = _mm256_set1_epi16(0x0F)
const __m256i hi_mask_16 = _mm256_set1_epi16(0xF0)
for (uint64_t b = 0
//
// Calculate the offsets
//
const uint64_t offset0 = b * 32
const uint64_t offset1 = b * 32 + 32
const uint64_t offset2 = b * 32 / 2
//
// Load 128 values in two AVX registers. Each register will
// contain 64 x 4-bit values in the range [-8, 7].
//
const __m256i qv_1 = _mm256_loadu_si256((__m256i *) (v + offset0))
const __m256i qv_2 = _mm256_loadu_si256((__m256i *) (v + offset1))
//
// Extract the odd and the even parts. The values will be split in
// two registers qv_odd_shift and qv_evn_shift, each of them having
// 32 x 8-bit values, such that each value is multiplied by 2^4
// and resides in the range [-8 * 2^4, 7 * 2^4]
//
const __m256i qv_odd_dirty_1 = _mm256_slli_epi16(qv_1, 4)
const __m256i qv_odd_shift_1 = _mm256_and_si256(hi_mask_08, qv_odd_dirty_1)
const __m256i qv_evn_shift_1 = _mm256_and_si256(hi_mask_08, qv_1)
const __m256i qv_odd_dirty_2 = _mm256_slli_epi16(qv_2, 4)
const __m256i qv_odd_shift_2 = _mm256_and_si256(hi_mask_08, qv_odd_dirty_2)
const __m256i qv_evn_shift_2 = _mm256_and_si256(hi_mask_08, qv_2)
//
// Perform addition. In case of overflows / underflows, behaviour
// is undefined. Values are still in the range [-8 * 2^4, 7 * 2^4].
//
const __m256i qv_sum_shift_1 = _mm256_add_epi8(qv_odd_shift_1, qv_evn_shift_1)
const __m256i qv_sum_shift_2 = _mm256_add_epi8(qv_odd_shift_2, qv_evn_shift_2)
//
// Divide by 2^4. At this point in time, each of the two AVX registers holds
// 32 x 8-bit values that are in the range of [-8, 7]. Summation is complete.
//
const __m256i qv_sum_1 = _mm256_srai_epi16(qv_sum_shift_1, 4)
const __m256i qv_sum_2 = _mm256_srai_epi16(qv_sum_shift_2, 4)
//
// Now, we want to take the even numbers of the 32 x 4-bit register, and
// store them in the high-bits of the odd numbers. We do this with
// left shifts that extend in zero, and 16-bit masks. This operation
// results in two registers qv_sum_lo and qv_sum_hi that hold 32
// values. However, each consecutive 4-bit values reside in the
// low-bits of a 16-bit chunk.
//
const __m256i qv_sum_1_lo = _mm256_and_si256(lo_mask_16, qv_sum_1)
const __m256i qv_sum_1_hi_dirty = _mm256_srli_epi16(qv_sum_shift_1, 8)
const __m256i qv_sum_1_hi = _mm256_and_si256(hi_mask_16, qv_sum_1_hi_dirty)
const __m256i qv_sum_2_lo = _mm256_and_si256(lo_mask_16, qv_sum_2)
const __m256i qv_sum_2_hi_dirty = _mm256_srli_epi16(qv_sum_shift_2, 8)
const __m256i qv_sum_2_hi = _mm256_and_si256(hi_mask_16, qv_sum_2_hi_dirty)
const __m256i qv_sum_16_1 = _mm256_or_si256(qv_sum_1_lo, qv_sum_1_hi)
const __m256i qv_sum_16_2 = _mm256_or_si256(qv_sum_2_lo, qv_sum_2_hi)
//
// Pack the two registers of 32 x 4-bit values, into a single one having
// 64 x 4-bit values. Use the unsigned version, to avoid saturation.
//
const __m256i qv_sum_pack = _mm256_packus_epi16(qv_sum_16_1, qv_sum_16_2)
//
// Interleave the 64-bit chunks.
//
const __m256i qv_sum = _mm256_permute4x64_epi64(qv_sum_pack, 0xD8)
//
// Store the result
//
_mm256_storeu_si256((__m256i *)(r + offset2), qv_sum)
}
}
这段代码的自包含测试器和验证器在此处的gist中可用。
奇偶4位条目的乘法
对于奇偶条目的乘法,我们可以使用上述相同的策略将4位数提取到更大的块中。
AVX2不提供8位乘法,只提供16位。但是,我们可以按照Agner Fog的C++向量类库中实现的方法实现8位乘法:
static inline Vec32c operator * (Vec32c const & a, Vec32c const & b) {
__m256i aodd = _mm256_srli_epi16(a,8);
__m256i bodd = _mm256_srli_epi16(b,8);
__m256i muleven = _mm256_mullo_epi16(a,b);
__m256i mulodd = _mm256_mullo_epi16(aodd,bodd);
mulodd = _mm256_slli_epi16(mulodd,8);
__m256i mask = _mm256_set1_epi32(0x00FF00FF);
__m256i product = selectb(mask,muleven,mulodd);
return product;
}
我建议先将nibbles抽取成16位块,然后使用_mm256_mullo_epi16以避免执行不必要的移位。
[1,8]+[1,8],那么[3,0]可以吗?还是你期望得到[2,0]或[2,F]?或者w应该由8位元素组成? - chtz