如果我请求以下网址:
我会得到一个不使用脚本的验证码版本,其中包含Google街景号码的图像,如下所示:
Google服务器如何区分浏览器和
以下是
http://www.google.com/recaptcha/api/noscript?k=MYPUBLICKEY
我会得到一个不使用脚本的验证码版本,其中包含Google街景号码的图像,如下所示:
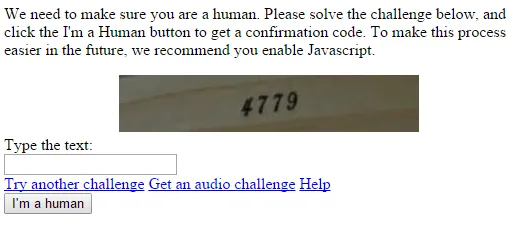
HtmlUnit进行相同的操作,我将得到一些伪造的图像版本,如下所示:

HtmlUnit获取黑色畸形的文本。公钥是相同的。Google服务器如何区分浏览器和
HtmlUnit?以下是
HtmlUnit代码:final WebClient webClient = new WebClient(BrowserVersion.FIREFOX_17);
final HtmlPage page = webClient.getPage("http://www.google.com/recaptcha/api/noscript?k=" + getPublicKey());
HtmlImage image = page.<HtmlImage>getFirstByXPath("//img");
ImageReader imageReader = image.getImageReader();
使用Fiddler可以观察进程。