首先,使用-O2 -rtsopts编译程序。然后,为了得到第一个可以优化的想法,使用选项+RTS -sstderr运行程序:
$ ./question +RTS -sstderr
[(0,1000000),(1000000,1000000),(2000000,1000000),(3000000,1000000),(4000000,1000000),(5000000,1000000),(6000000,1000000),(7000000,1000000),(8000000,1000000),(9000000,1000000)]
1,193,907,224 bytes allocated in the heap
1,078,027,784 bytes copied during GC
282,023,968 bytes maximum residency (7 sample(s))
86,755,184 bytes maximum slop
763 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 1964 colls, 0 par 3.99s 4.05s 0.0021s 0.0116s
Gen 1 7 colls, 0 par 1.60s 1.68s 0.2399s 0.6665s
INIT time 0.00s ( 0.00s elapsed)
MUT time 2.67s ( 2.68s elapsed)
GC time 5.59s ( 5.73s elapsed)
EXIT time 0.02s ( 0.03s elapsed)
Total time 8.29s ( 8.43s elapsed)
Alloc rate 446,869,876 bytes per MUT second
Productivity 32.6
注意到你的时间中有67%花在了垃圾回收上!显然有些问题。为了找出问题所在,我们可以使用堆分析来运行程序(使用+RTS -h),它会生成以下图表:
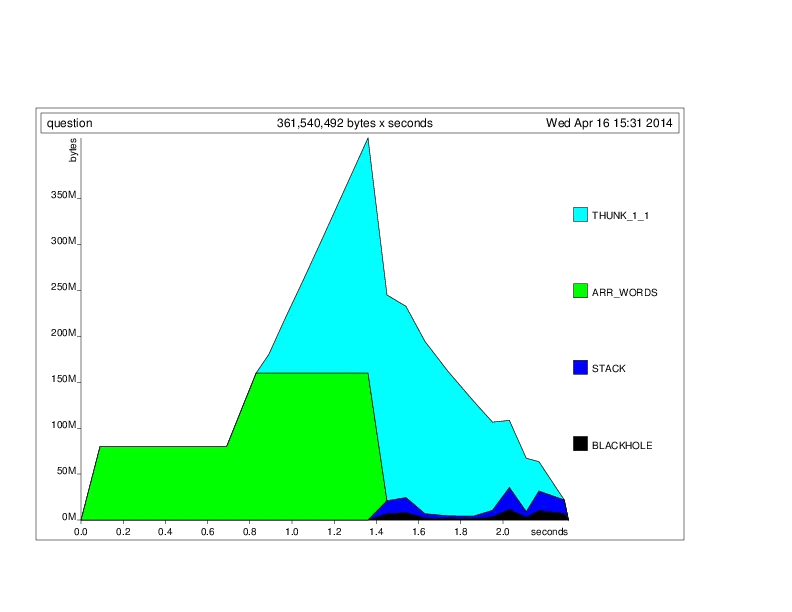
所以,你正在泄漏thunks。这是怎么发生的?查看代码,唯一一个递归建立thunk的地方是在添加操作中的agg。通过添加bang模式使cv强制执行即可解决此问题:
{-# LANGUAGE BangPatterns #-}
import qualified Data.Vector.Unboxed as V
histogram :: [(Int,Int)]
histogram = V.foldr' agg [] $ V.zip k v
where
n = 10000000
c = 1000000
k = V.generate n (\i -> i `div` c * c)
v = V.generate n id
agg kv [] = [kv]
agg kv@(k,v) acc@((ck,!cv):as)
| k == ck = (ck,cv+v):as
| otherwise = kv:acc
main :: IO ()
main = print histogram
输出:
$ time ./improved +RTS -sstderr
[(0,499999500000),(1000000,1499999500000),(2000000,2499999500000),(3000000,3499999500000),(4000000,4499999500000),(5000000,5499999500000),(6000000,6499999500000),(7000000,7499999500000),(8000000,8499999500000),(9000000,9499999500000)]
672,063,056 bytes allocated in the heap
94,664 bytes copied during GC
160,028,816 bytes maximum residency (2 sample(s))
1,464,176 bytes maximum slop
155 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 992 colls, 0 par 0.03s 0.03s 0.0000s 0.0001s
Gen 1 2 colls, 0 par 0.03s 0.03s 0.0161s 0.0319s
INIT time 0.00s ( 0.00s elapsed)
MUT time 1.24s ( 1.25s elapsed)
GC time 0.06s ( 0.06s elapsed)
EXIT time 0.03s ( 0.03s elapsed)
Total time 1.34s ( 1.34s elapsed)
Alloc rate 540,674,868 bytes per MUT second
Productivity 95.5
./improved +RTS -sstderr 1,14s user 0,20s system 99
这好多了。
现在你可能会问,既然使用了seq,为什么问题还是出现了呢?原因是seq只强制第一个参数进入WHNF状态,对于一对(_,_)(其中_是未计算的thunks),它已经处于WHNF状态!另外,seq a a与a是相同的,因为seq a b(非正式地)意味着:在评估b之前评估a,所以seq a a仅意味着:在评估a之前评估a,这与评估a本身相同!
-O2而不是简单的-O。当您仅使用-O时,我不确定它的默认设置是什么。 - Sibi-O”与“-O1”相同,所以确实应该尝试使用“-O2”。 - bennofsquot比div更快。 - Franky