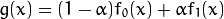我正在使用OpenCV android 2.4.11的示例,该示例使用相机检测人脸。 我尝试在找到的脸上放置一个口罩(png图像),而不是在脸上绘制矩形。 但是要在脸上显示图像,png图像会带有黑色背景,其中原本应该是透明的。
FdActivity.java
public void onCameraViewStarted(int width, int height) {
mGray = new Mat();
mRgba = new Mat();
//Load my mask png
Bitmap image = BitmapFactory.decodeResource(getResources(), R.drawable.mask_1);
mask = new Mat();
Utils.bitmapToMat(image, mask);
}
public Mat onCameraFrame(CvCameraViewFrame inputFrame) {
mRgba = inputFrame.rgba();
mGray = inputFrame.gray();
if (mAbsoluteFaceSize == 0) {
int height = mGray.rows();
if (Math.round(height * mRelativeFaceSize) > 0) {
mAbsoluteFaceSize = Math.round(height * mRelativeFaceSize);
}
mNativeDetector.setMinFaceSize(mAbsoluteFaceSize);
}
MatOfRect faces = new MatOfRect();
if (mDetectorType == JAVA_DETECTOR) {
if (mJavaDetector != null)
mJavaDetector.detectMultiScale(mGray, faces, 1.1, 2, 2,
new Size(mAbsoluteFaceSize, mAbsoluteFaceSize), new Size());
}
else if (mDetectorType == NATIVE_DETECTOR) {
if (mNativeDetector != null)
mNativeDetector.detect(mGray, faces);
}
else {
Log.e(TAG, "Detection method is not selected!");
}
Rect[] facesArray = faces.toArray();
for (int i = 0; i < facesArray.length; i++) {
overlayImage(mRgba, mask, facesArray[i]);
}
return mRgba;
}
public Mat overlayImage(Mat background, Mat foregroundMask, Rect faceRect)
{
Mat mask = new Mat();
Imgproc.resize(this.mask, mask, faceRect.size());
Mat source = new Mat();
Imgproc.resize(foregroundMask, source, background.size());
mask.copyTo( background.submat( new Rect((int) faceRect.tl().x, (int) faceRect.tl().y, mask.cols(), mask.rows())) );
source.release();
mask.release();
return background;
}