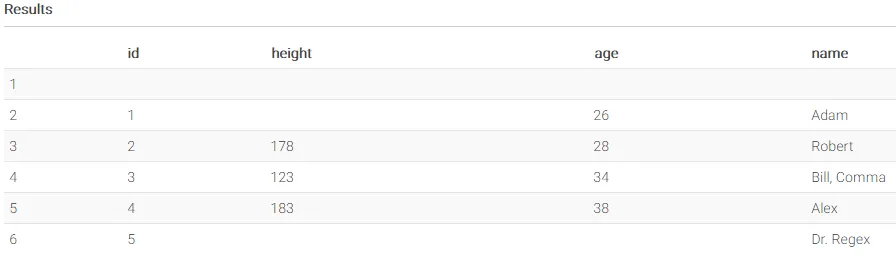
我正在尝试使用存储在S3上的带引号的CSV文件在Athena中创建外部表。问题是,我的CSV文件中包含应该读取为INT的列中缺失的值。以下是一个简单的例子:
CSV文件:
id,height,age,name
1,,26,"Adam"
2,178,28,"Robert"
创建表定义:
CREATE EXTERNAL TABLE schema.test_null_unquoted (
id INT,
height INT,
age INT,
name STRING
)
ROW FORMAT
SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ",",
'quoteChar' = '"',
'skip.header.line.count' = '1'
)
STORED AS TEXTFILE
LOCATION 's3://mybucket/test_null/unquoted/'
CREATE TABLE 语句运行良好,但是一旦我尝试查询表格,就会收到 HIVE_BAD_DATA: Error parsing field value '' 的错误信息。
我尝试将 CSV 格式更改为以下形式(引用空字符串):
"id","height","age","name"
1,"",26,"Adam"
2,178,28,"Robert"
但是它不起作用。
尝试在SERDEPROPERTIES中指定'serialization.null.format' = '' - 无效。
尝试通过TBLPROPERTIES ('serialization.null.format'='')进行相同的指定 - 仍然没有结果。
当您将所有列指定为STRING时,它可以工作,但这不是我所需要的。
因此,问题是,是否有任何方法可以使用正确的列规范将带引号的CSV(引号很重要,因为我的实际数据更加复杂)读入Athena?