我正在使用
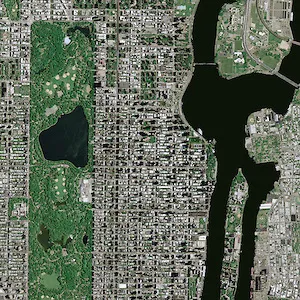
在我的情况下,我必须训练一个在城区拍摄的 SAR 卫星图像,并且我需要对城市区域、道路、河流和植被(4 个类)进行分类。这张图片有两个波段,但我没有每个类别的标签数据,就像 Iris 数据一样。
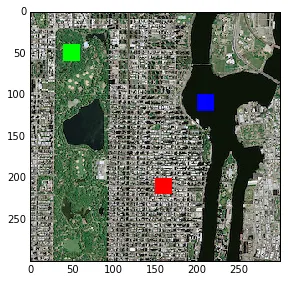
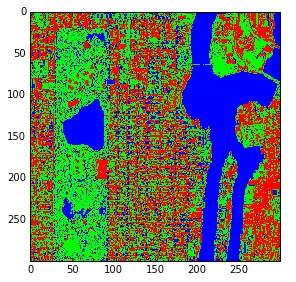
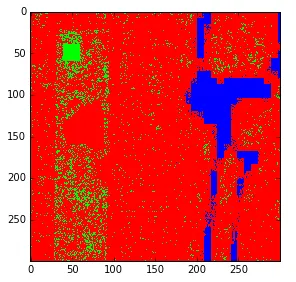
那么,我的问题是,我是否必须手动创建矢量数据(用于 4 类)以便训练 SVM 模型?有没有比手动创建矢量数据更容易的训练模型的方法?在这种情况下,我们该怎么做?
说实话,我有点困惑。我会感激任何帮助。
scikit-learn 库对卫星图像执行监督分类(支持向量机分类器)。我的主要问题是如何训练我的 SVM 分类器。我在 YouTube 上观看了许多视频,并阅读了一些关于如何在 scikit-learn 中训练 SVM 模型的教程。我所看到的所有教程都是使用著名的 Iris 数据集。为了在 scikit-learn 中执行监督式 SVM 分类,我们需要有标签。对于 Iris 数据集,我们有 Iris.target,它是我们试图预测的标签(“setosa”,“versicolor”,“virginica”)。通过阅读 scikit-learn 的文档,训练过程很简单。在我的情况下,我必须训练一个在城区拍摄的 SAR 卫星图像,并且我需要对城市区域、道路、河流和植被(4 个类)进行分类。这张图片有两个波段,但我没有每个类别的标签数据,就像 Iris 数据一样。
那么,我的问题是,我是否必须手动创建矢量数据(用于 4 类)以便训练 SVM 模型?有没有比手动创建矢量数据更容易的训练模型的方法?在这种情况下,我们该怎么做?
说实话,我有点困惑。我会感激任何帮助。