我想在这里应用决策树。决策树会自行处理每个节点的分割。但是,在第一个节点上,我想基于"年龄"进行分割。该如何强制执行呢?
library(party)
fit2 <- ctree(Churn ~ Gender + Age + LastTransaction + Payment.Method + spend + marStat, data = tsdata)
我想在这里应用决策树。决策树会自行处理每个节点的分割。但是,在第一个节点上,我想基于"年龄"进行分割。该如何强制执行呢?
library(party)
fit2 <- ctree(Churn ~ Gender + Age + LastTransaction + Payment.Method + spend + marStat, data = tsdata)
ctree()中没有内置选项可以实现此功能。手动完成这个最简单的方法是:
只使用解释变量Age和maxdepth = 1学习一棵树,以便只创建一个分裂。
使用步骤1中的树拆分数据并为左分支创建子树。
使用步骤1中的树拆分数据并为右分支创建子树。
这将实现您想要的效果(尽管我通常不建议这样做...)。
如果您使用partykit中的ctree()实现,则还可以将这三棵树合并成单个树,以进行可视化和预测等操作。这需要进行一些修改,但仍然可行。
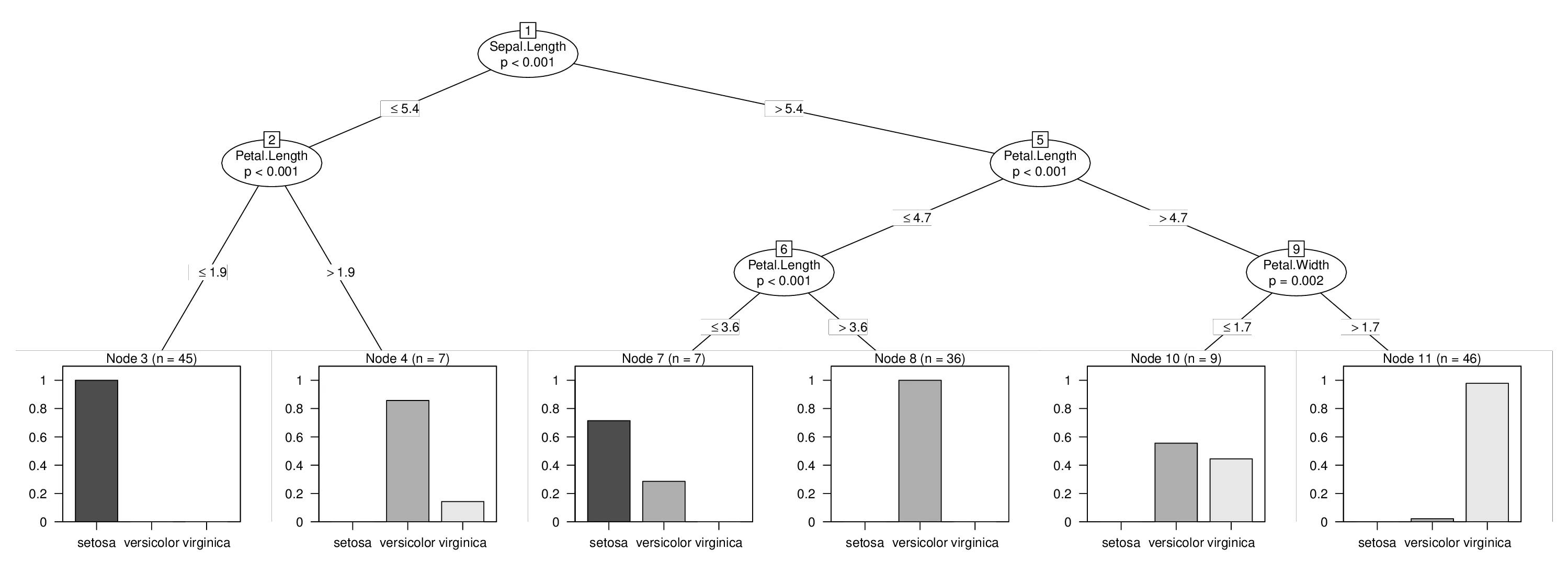
我将使用iris数据并强制在变量Sepal.Length中进行分裂,否则该树不会使用该变量。学习上述三棵树非常容易:
library("partykit")
data("iris", package = "datasets")
tr1 <- ctree(Species ~ Sepal.Length, data = iris, maxdepth = 1)
tr2 <- ctree(Species ~ Sepal.Length + ., data = iris,
subset = predict(tr1, type = "node") == 2)
tr3 <- ctree(Species ~ Sepal.Length + ., data = iris,
subset = predict(tr1, type = "node") == 3)
需要注意的是,使用公式Sepal.Length + .非常重要,以确保模型框架中的变量在所有树中都按相同方式排序。
接下来是最技术性的步骤:我们需要从三棵树中提取原始node结构,修复节点id,使其处于正确的顺序,然后将所有内容整合成单个节点:
fixids <- function(x, startid = 1L) {
id <- startid - 1L
new_node <- function(x) {
id <<- id + 1L
if(is.terminal(x)) return(partynode(id, info = info_node(x)))
partynode(id,
split = split_node(x),
kids = lapply(kids_node(x), new_node),
surrogates = surrogates_node(x),
info = info_node(x))
}
return(new_node(x))
}
no <- node_party(tr1)
no$kids <- list(
fixids(node_party(tr2), startid = 2L),
fixids(node_party(tr3), startid = 5L)
)
no
## [1] root
## | [2] V2 <= 5.4
## | | [3] V4 <= 1.9 *
## | | [4] V4 > 1.9 *
## | [5] V2 > 5.4
## | | [6] V4 <= 4.7
## | | | [7] V4 <= 3.6 *
## | | | [8] V4 > 3.6 *
## | | [9] V4 > 4.7
## | | | [10] V5 <= 1.7 *
## | | | [11] V5 > 1.7 *
最后,我们设置了一个包含所有数据的联合模型框架,并将其与新的联合树结合起来。为了能够将树转化为 constparty 以进行良好的可视化和预测,添加了一些关于拟合节点和响应的信息。有关此背景,请参见 vignette("partykit", package = "partykit"):
d <- model.frame(Species ~ Sepal.Length + ., data = iris)
tr <- party(no,
data = d,
fitted = data.frame(
"(fitted)" = fitted_node(no, data = d),
"(response)" = model.response(d),
check.names = FALSE),
terms = terms(d),
)
tr <- as.constparty(tr)
然后我们完成了,可以使用强制第一个分割来可视化我们合并的树:
plot(tr)
library(rpart)
fit2 <- rpart(Churn ~ . -(Gendere + LastTransaction + Payment.Method + spend + marStat) , data = tsdata, maxdepth = 1)
library(partykit)
fit2party <- as.party(fit2)
dataset1 <- data_party(fit2party, id = 2)
dataset2 <- data_party(fit2party, id = 3)
现在你有两个数据集,基于年龄分割,并且包含了你未来训练决策树所需的所有变量。你可以根据自己的需要使用rpart或ctree构建决策树。
之后,你可以使用partynode和partysplit组合来根据你所达到的训练规则构建树形结构。
希望这正是你所需要的。