我想询问是否有可能比较两个巨大数据库的完整结构。 我们有两个数据库,一个是开发数据库,另一个是生产数据库。 有时候在发布一些代码之前,我会忘记将更改应用到生产数据库中,这导致生产数据库的结构与开发数据库不同,如果有东西需要发布,我们就会遇到一些错误。 有没有办法比较这两个数据库或进行同步?
8个回答
42
对于MySQL数据库,您可以使用以下查询比较视图和表(列名称和列类型):
SET @firstDatabaseName = '[first database name]';
SET @secondDatabaseName = '[second database name]';
SELECT * FROM
(SELECT
CONCAT(cl.TABLE_NAME, ' [', cl.COLUMN_NAME, ', ', cl.COLUMN_TYPE, ']') tableRowType
FROM information_schema.columns cl, information_schema.TABLES ss
WHERE
cl.TABLE_NAME = ss.TABLE_NAME AND
cl.TABLE_SCHEMA = @firstDatabaseName AND
ss.TABLE_TYPE IN('BASE TABLE', 'VIEW')
ORDER BY
cl.table_name ) AS t1
LEFT JOIN
(SELECT
CONCAT(cl.TABLE_NAME, ' [', cl.COLUMN_NAME, ', ', cl.COLUMN_TYPE, ']') tableRowType
FROM information_schema.columns cl, information_schema.TABLES ss
WHERE
cl.TABLE_NAME = ss.TABLE_NAME AND
cl.TABLE_SCHEMA = @secondDatabaseName AND
ss.TABLE_TYPE IN('BASE TABLE', 'VIEW')
ORDER BY
cl.table_name ) AS t2 ON t1.tableRowType = t2.tableRowType
WHERE
t2.tableRowType IS NULL
UNION
SELECT * FROM
(SELECT
CONCAT(cl.TABLE_NAME, ' [', cl.COLUMN_NAME, ', ', cl.COLUMN_TYPE, ']') tableRowType
FROM information_schema.columns cl, information_schema.TABLES ss
WHERE
cl.TABLE_NAME = ss.TABLE_NAME AND
cl.TABLE_SCHEMA = @firstDatabaseName AND
ss.TABLE_TYPE IN('BASE TABLE', 'VIEW')
ORDER BY
cl.table_name ) AS t1
RIGHT JOIN
(SELECT
CONCAT(cl.TABLE_NAME, ' [', cl.COLUMN_NAME, ', ', cl.COLUMN_TYPE, ']') tableRowType
FROM information_schema.columns cl, information_schema.TABLES ss
WHERE
cl.TABLE_NAME = ss.TABLE_NAME AND
cl.TABLE_SCHEMA = @secondDatabaseName AND
ss.TABLE_TYPE IN('BASE TABLE', 'VIEW')
ORDER BY
cl.table_name ) AS t2 ON t1.tableRowType = t2.tableRowType
WHERE
t1.tableRowType IS NULL;
如果您偏爱使用带用户界面的工具,您也可以使用这个脚本https://github.com/dlevsha/compalex,它可以比较表、视图、键等。
Compalex是一个轻量级的脚本,用于比较两个数据库模式。它支持MySQL、MS SQL Server和PostgreSQL。
截图(比较表格)
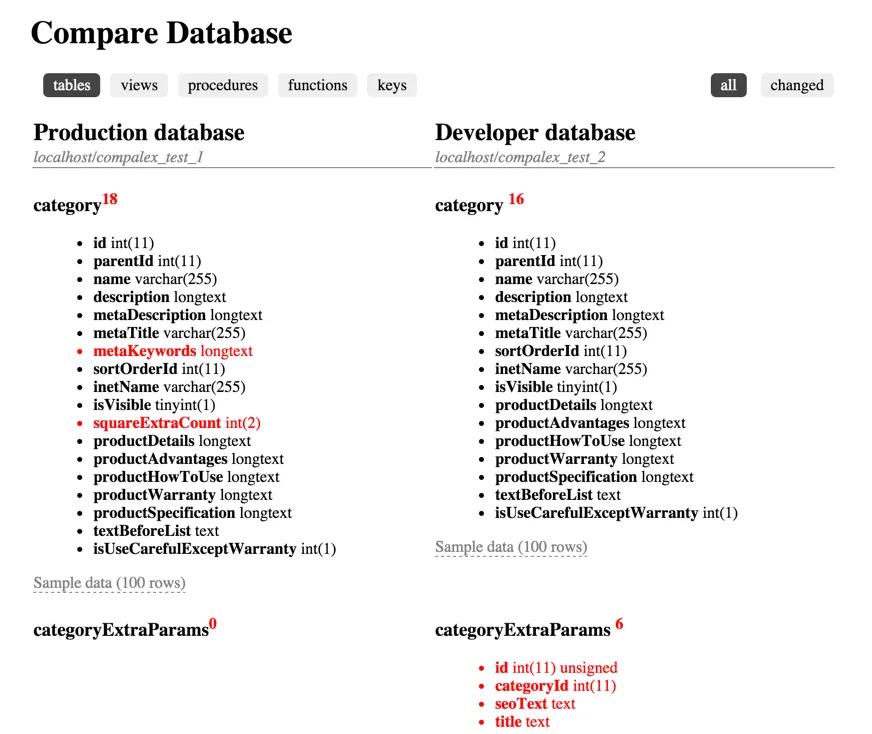
- Dmitry
4
这太棒了。我使用它。谢谢。 - Taufik Nur Rahmanda
1Compalex很棒(+1),但不显示索引。它也会显示,但不会突出显示引擎(MyISAM vs InnoDB)中的差异。 - TRiG
1@TRiG 最新的Compalex版本显示索引。http://demo.compalex.net/index.php?action=indexes - Digvijayad
是的,这很有帮助进行比较。 :D - Vipertecpro
22
你可以使用命令行:
mysqldump --skip-comments --skip-extended-insert -d --no-data -u root -p dbName1>file1.sql
mysqldump --skip-comments --skip-extended-insert -d --no-data -u root -p dbName2>file2.sql
diff file1.sql file2.sql
- Gere
5
1不错的想法,Gere。使用diff命令很容易找到差异,但是表名却不好找,所以我转而使用了tkdiff包。我强烈推荐它。 - therealbigpepe
如何跳过自动递增? - Arun Gowda
@ArunGowda 或许可以添加一个正则表达式,例如 | sed 's/ AUTO_INCREMENT=[0-9]*//g' (在 dbName 之后)。 - Gere
@suarsenegger 为什么 diff 命令不能显示表名的差异? - kojow7
1现在最好的GUI差异工具是VSCode,使用
compare file命令。 - undefined6
为了回答这种问题,我编写了一个脚本,使用
希望这个脚本也可以帮助那些寻找非应用程序解决方案的人,而是使用脚本。干杯!
information_schema 的内容来比较列、数据类型和表。SET @database_current = '<production>';
SET @database_dev = '<development>';
-- column and datatype comparison
SELECT a.TABLE_NAME, a.COLUMN_NAME, a.DATA_TYPE, a.CHARACTER_MAXIMUM_LENGTH,
b.COLUMN_NAME, b.DATA_TYPE, b.CHARACTER_MAXIMUM_LENGTH
FROM information_schema.COLUMNS a
LEFT JOIN information_schema.COLUMNS b ON b.COLUMN_NAME = a.COLUMN_NAME
AND b.TABLE_NAME = a.TABLE_NAME
AND b.TABLE_SCHEMA = @database_current
WHERE a.TABLE_SCHEMA = @database_dev
AND (
b.COLUMN_NAME IS NULL
OR b.COLUMN_NAME != a.COLUMN_NAME
OR b.DATA_TYPE != a.DATA_TYPE
OR b.CHARACTER_MAXIMUM_LENGTH != a.CHARACTER_MAXIMUM_LENGTH
);
-- table comparison
SELECT a.TABLE_SCHEMA, a.TABLE_NAME, b.TABLE_NAME
FROM information_schema.TABLES a
LEFT JOIN information_schema.TABLES b ON b.TABLE_NAME = a.TABLE_NAME
AND b.TABLE_SCHEMA = @database_current
WHERE a.TABLE_SCHEMA = @database_dev
AND (
b.TABLE_NAME IS NULL
OR b.TABLE_NAME != a.TABLE_NAME
);
希望这个脚本也可以帮助那些寻找非应用程序解决方案的人,而是使用脚本。干杯!
- Avidos
3
1我喜欢你使用仅限于mysql的解决方案的想法。然而,过滤器OR b.COLUMN_NAME!= a.COLUMN_NAME是多余的,因为在JOIN条件中已经假定了等价性,同样的,OR b.TABLE_NAME!= a.TABLE_NAME也是如此。 - Paul Campbell
@PaulCampbell 很好的观点!感谢您的帮助,非常感激。干杯 - Avidos
此解决方案未考虑索引,需要添加一个单独的块来处理它们。 - Andrei Rykhalski
5
你可以使用 --no-data 参数将它们导出并比较文件。
请记得在生产数据库上使用 --lock-tables=0 选项,以避免出现大量的全局锁问题。
如果你使用相同的 mysqldump 版本(你的 dev 和 production 系统应该有相同的软件版本),那么你会期望获得几乎相同的文件。表格将按字母顺序排列,因此简单的 diff 命令可以轻松地显示出差异。
请记得在生产数据库上使用 --lock-tables=0 选项,以避免出现大量的全局锁问题。
如果你使用相同的 mysqldump 版本(你的 dev 和 production 系统应该有相同的软件版本),那么你会期望获得几乎相同的文件。表格将按字母顺序排列,因此简单的 diff 命令可以轻松地显示出差异。
- MarkR
2
对于Linux上的mysql,可以通过phpmyadmin仅导出数据库结构而不包含数据。在导出整个数据库时,只需取消选择“数据”并设置输出为文本格式。导出你想要比较的两个数据库。
然后,在你喜欢的程序/网站中进行文件比较,比较这两个数据库的文本文件输出。虽然此解决方案仍需要手动同步,但对于比较和查找结构差异非常有效。
然后,在你喜欢的程序/网站中进行文件比较,比较这两个数据库的文本文件输出。虽然此解决方案仍需要手动同步,但对于比较和查找结构差异非常有效。
- Paul V
1
对于我所需要的非常简单的比较,这是一种低开销和快速的方法。谢谢! - user1072910
2
我尝试使用mysqldiff,但没有成功,所以我想通过提醒mysqlworkbench的比较功能来丰富未来读者的知识。如果您打开模型选项卡并选择数据库菜单,则会获得“比较模式”选项,您可以使用它来比较两个不同服务器上的不同模式,或同一服务器上的两个模式,或一个模式和一个模型,或许多其他我尚未尝试过的选项。详情请参阅http://dev.mysql.com/doc/workbench/en/wb-database-diff-report.html#c13030。请注意保留HTML标签。
- JoSSte
1
请查看针对.NET的Gemini Delta - SQL差异管理器。免费测试版可供下载,但完整版本距离公开发布仅有几天。
它不会比较行级数据差异,但它会比较表、函数、存储过程等,并且速度非常快。(新版本1.4在不到4秒的时间内加载和比较了1k个存储过程,而其他我测试过的工具需要超过10秒。)
尽管如此,大家都是正确的,RedGate确实制作出了很棒的工具。
- Shaun
1
根据您使用的数据库,可用的工具也会有所不同。
我使用 Embarcadero 的 ER/Studio。它具有比较和合并功能。
还有很多其他工具,例如 Toad for MySQL,也具有比较功能。我也同意 Red-Gate 的建议,但从未在 MySQL 上使用过它。
- codenheim
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接