我已经处理了几个小时。我正在保存一个包含波兰重音符号
.Net字符串由UTF-16字符组成,因此我一直在使用以下代码将Unicode转换为Mazovia。
ąśółńźć等的字符串到文件中,但我必须使用的软件只能读取Mazovia编码,这是一种相当古老的编码,不被Microsoft Encoding类支持。.Net字符串由UTF-16字符组成,因此我一直在使用以下代码将Unicode转换为Mazovia。
string rekord = (linia.Substring(0, linia.Length - 1)) + Environment.NewLine;
string rekordMazovia = Kodowanie.UnicodeNaMazovia(rekord);
File.AppendAllText(sciezka, rekordMazovia);
public static class Kodowanie {
public static string UnicodeNaMazovia(string tekst) {
return tekst
.Replace((char)0x104, (char)0x8F) //Ą
.Replace((char)0x106, (char)0x95) //Ć
.Replace((char)0x118, (char)0x90) //Ę
.Replace((char)0x141, (char)0x9C) //Ł
.Replace((char)0x143, (char)0xA5) //Ń
.Replace((char)0xD3, (char)0xA3) //Ó
.Replace((char)0x15A, (char)0x98) //Ś
.Replace((char)0x179, (char)0xA0) //Ź
.Replace((char)0x17B, (char)0xA1) //Ż
.Replace((char)0x105, (char)0x86) //ą
.Replace((char)0x107, (char)0x8D) //ć
.Replace((char)0x119, (char)0x91) //ę
.Replace((char)0x142, (char)0x92) //ł
.Replace((char)0x144, (char)0xA4) //ń
.Replace((char)0xF3, (char)0xA2) //ó
.Replace((char)0x15B, (char)0x9E) //ś
.Replace((char)0x17A, (char)0xA6) //ź
.Replace((char)0x17C, (char)0xA7); //ż
}
}
除了在应用程序中读取生成的文件后,每个变音符号前都有一个多余字符>之外,一切都很正常。它看起来像这样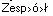
如何消除它? 如何更好地做到这一点?
Encoding.GetEncoding(437)获取相应的System.Text.Encoding。这将返回System.Text.SBCSCodePageEncoding。这对您不起作用吗? - Ravi Y