我正在解决一个问题,涉及快速排序10个数字(int32)。我的应用程序需要尽可能快地对10个数字进行数百万次的排序。我正在对数十亿个元素的数据集进行抽样,每次需要从中选择10个数字(简化),并对它们进行排序(并从排序后的10个元素列表中得出结论)。
目前我正在使用插入排序,但我想我可以为我的特定问题实现一个非常快速的自定义排序算法,以打败插入排序。
我该如何解决这个问题?
我正在解决一个问题,涉及快速排序10个数字(int32)。我的应用程序需要尽可能快地对10个数字进行数百万次的排序。我正在对数十亿个元素的数据集进行抽样,每次需要从中选择10个数字(简化),并对它们进行排序(并从排序后的10个元素列表中得出结论)。
目前我正在使用插入排序,但我想我可以为我的特定问题实现一个非常快速的自定义排序算法,以打败插入排序。
我该如何解决这个问题?
(跟进@HelloWorld的建议,研究排序网络。)
似乎使用29次比较/交换的网络是实现10个输入排序的最快方法。我在JavaScript中使用了Waksman在1969年发现的网络作为这个示例,这应该可以直接转换成C,因为它只是一系列if语句、比较和交换。
function sortNet10(data) { // ten-input sorting network by Waksman, 1969
var swap;
if (data[0] > data[5]) { swap = data[0]; data[0] = data[5]; data[5] = swap; }
if (data[1] > data[6]) { swap = data[1]; data[1] = data[6]; data[6] = swap; }
if (data[2] > data[7]) { swap = data[2]; data[2] = data[7]; data[7] = swap; }
if (data[3] > data[8]) { swap = data[3]; data[3] = data[8]; data[8] = swap; }
if (data[4] > data[9]) { swap = data[4]; data[4] = data[9]; data[9] = swap; }
if (data[0] > data[3]) { swap = data[0]; data[0] = data[3]; data[3] = swap; }
if (data[5] > data[8]) { swap = data[5]; data[5] = data[8]; data[8] = swap; }
if (data[1] > data[4]) { swap = data[1]; data[1] = data[4]; data[4] = swap; }
if (data[6] > data[9]) { swap = data[6]; data[6] = data[9]; data[9] = swap; }
if (data[0] > data[2]) { swap = data[0]; data[0] = data[2]; data[2] = swap; }
if (data[3] > data[6]) { swap = data[3]; data[3] = data[6]; data[6] = swap; }
if (data[7] > data[9]) { swap = data[7]; data[7] = data[9]; data[9] = swap; }
if (data[0] > data[1]) { swap = data[0]; data[0] = data[1]; data[1] = swap; }
if (data[2] > data[4]) { swap = data[2]; data[2] = data[4]; data[4] = swap; }
if (data[5] > data[7]) { swap = data[5]; data[5] = data[7]; data[7] = swap; }
if (data[8] > data[9]) { swap = data[8]; data[8] = data[9]; data[9] = swap; }
if (data[1] > data[2]) { swap = data[1]; data[1] = data[2]; data[2] = swap; }
if (data[3] > data[5]) { swap = data[3]; data[3] = data[5]; data[5] = swap; }
if (data[4] > data[6]) { swap = data[4]; data[4] = data[6]; data[6] = swap; }
if (data[7] > data[8]) { swap = data[7]; data[7] = data[8]; data[8] = swap; }
if (data[1] > data[3]) { swap = data[1]; data[1] = data[3]; data[3] = swap; }
if (data[4] > data[7]) { swap = data[4]; data[4] = data[7]; data[7] = swap; }
if (data[2] > data[5]) { swap = data[2]; data[2] = data[5]; data[5] = swap; }
if (data[6] > data[8]) { swap = data[6]; data[6] = data[8]; data[8] = swap; }
if (data[2] > data[3]) { swap = data[2]; data[2] = data[3]; data[3] = swap; }
if (data[4] > data[5]) { swap = data[4]; data[4] = data[5]; data[5] = swap; }
if (data[6] > data[7]) { swap = data[6]; data[6] = data[7]; data[7] = swap; }
if (data[3] > data[4]) { swap = data[3]; data[3] = data[4]; data[4] = swap; }
if (data[5] > data[6]) { swap = data[5]; data[5] = data[6]; data[6] = swap; }
return(data);
}
document.write(sortNet10([5,7,1,8,4,3,6,9,2,0]));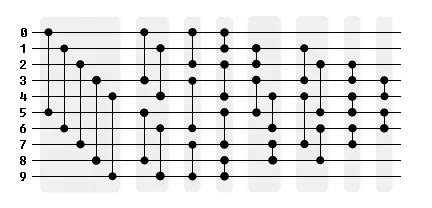
#define SORTPAIR(data, i1, i2) if (data[i1] > data[i2]) { int swap = data[i1]... }。 - Peter Cordes使用展开循环和无分支选择排序怎么样?
#include <iostream>
#include <algorithm>
#include <random>
//return the index of the minimum element in array a
int min(const int * const a) {
int m = a[0];
int indx = 0;
#define TEST(i) (m > a[i]) && (m = a[i], indx = i );
//see https://dev59.com/NGw05IYBdhLWcg3wuUAL#7074042
TEST(1);
TEST(2);
TEST(3);
TEST(4);
TEST(5);
TEST(6);
TEST(7);
TEST(8);
TEST(9);
#undef TEST
return indx;
}
void sort( int * const a ){
int work[10];
int indx;
#define GET(i) indx = min(a); work[i] = a[indx]; a[indx] = 2147483647;
//get the minimum, copy it to work and set it at max_int in a
GET(0);
GET(1);
GET(2);
GET(3);
GET(4);
GET(5);
GET(6);
GET(7);
GET(8);
GET(9);
#undef GET
#define COPY(i) a[i] = work[i];
//copy back to a
COPY(0);
COPY(1);
COPY(2);
COPY(3);
COPY(4);
COPY(5);
COPY(6);
COPY(7);
COPY(8);
COPY(9);
#undef COPY
}
int main() {
//generating and printing a random array
int a[10] = { 1,2,3,4,5,6,7,8,9,10 };
std::random_device rd;
std::mt19937 g(rd());
std::shuffle( a, a+10, g);
for (int i = 0; i < 10; i++) {
std::cout << a[i] << ' ';
}
std::cout << std::endl;
//sorting and printing again
sort(a);
for (int i = 0; i < 10; i++) {
std::cout << a[i] << ' ';
}
return 0;
}
http://coliru.stacked-crooked.com/a/71e18bc4f7fa18c6
只有前两个#define是相关的。
它使用了两个列表,并且完全重新检查第一个列表十次,这将是一种糟糕实现的选择排序算法。尽管如此,它避免了分支和可变长度循环,这可能会弥补现代处理器和如此小的数据集之间的差距。
我对排序网络进行了基准测试,我的代码似乎比它慢。然而,我尝试去除展开和拷贝。运行这段代码:
#include <iostream>
#include <algorithm>
#include <random>
#include <chrono>
int min(const int * const a, int i) {
int m = a[i];
int indx = i++;
for ( ; i<10; i++)
//see https://dev59.com/NGw05IYBdhLWcg3wuUAL#7074042
(m > a[i]) && (m = a[i], indx = i );
return indx;
}
void sort( int * const a ){
for (int i = 0; i<9; i++)
std::swap(a[i], a[min(a,i)]); //search only forward
}
void sortNet10(int * const data) { // ten-input sorting network by Waksman, 1969
int swap;
if (data[0] > data[5]) { swap = data[0]; data[0] = data[5]; data[5] = swap; }
if (data[1] > data[6]) { swap = data[1]; data[1] = data[6]; data[6] = swap; }
if (data[2] > data[7]) { swap = data[2]; data[2] = data[7]; data[7] = swap; }
if (data[3] > data[8]) { swap = data[3]; data[3] = data[8]; data[8] = swap; }
if (data[4] > data[9]) { swap = data[4]; data[4] = data[9]; data[9] = swap; }
if (data[0] > data[3]) { swap = data[0]; data[0] = data[3]; data[3] = swap; }
if (data[5] > data[8]) { swap = data[5]; data[5] = data[8]; data[8] = swap; }
if (data[1] > data[4]) { swap = data[1]; data[1] = data[4]; data[4] = swap; }
if (data[6] > data[9]) { swap = data[6]; data[6] = data[9]; data[9] = swap; }
if (data[0] > data[2]) { swap = data[0]; data[0] = data[2]; data[2] = swap; }
if (data[3] > data[6]) { swap = data[3]; data[3] = data[6]; data[6] = swap; }
if (data[7] > data[9]) { swap = data[7]; data[7] = data[9]; data[9] = swap; }
if (data[0] > data[1]) { swap = data[0]; data[0] = data[1]; data[1] = swap; }
if (data[2] > data[4]) { swap = data[2]; data[2] = data[4]; data[4] = swap; }
if (data[5] > data[7]) { swap = data[5]; data[5] = data[7]; data[7] = swap; }
if (data[8] > data[9]) { swap = data[8]; data[8] = data[9]; data[9] = swap; }
if (data[1] > data[2]) { swap = data[1]; data[1] = data[2]; data[2] = swap; }
if (data[3] > data[5]) { swap = data[3]; data[3] = data[5]; data[5] = swap; }
if (data[4] > data[6]) { swap = data[4]; data[4] = data[6]; data[6] = swap; }
if (data[7] > data[8]) { swap = data[7]; data[7] = data[8]; data[8] = swap; }
if (data[1] > data[3]) { swap = data[1]; data[1] = data[3]; data[3] = swap; }
if (data[4] > data[7]) { swap = data[4]; data[4] = data[7]; data[7] = swap; }
if (data[2] > data[5]) { swap = data[2]; data[2] = data[5]; data[5] = swap; }
if (data[6] > data[8]) { swap = data[6]; data[6] = data[8]; data[8] = swap; }
if (data[2] > data[3]) { swap = data[2]; data[2] = data[3]; data[3] = swap; }
if (data[4] > data[5]) { swap = data[4]; data[4] = data[5]; data[5] = swap; }
if (data[6] > data[7]) { swap = data[6]; data[6] = data[7]; data[7] = swap; }
if (data[3] > data[4]) { swap = data[3]; data[3] = data[4]; data[4] = swap; }
if (data[5] > data[6]) { swap = data[5]; data[5] = data[6]; data[6] = swap; }
}
std::chrono::duration<double> benchmark( void(*func)(int * const), const int seed ) {
std::mt19937 g(seed);
int a[10] = {10,11,12,13,14,15,16,17,18,19};
std::chrono::high_resolution_clock::time_point t1, t2;
t1 = std::chrono::high_resolution_clock::now();
for (long i = 0; i < 1e7; i++) {
std::shuffle( a, a+10, g);
func(a);
}
t2 = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::duration<double>>(t2 - t1);
}
int main() {
std::random_device rd;
for (int i = 0; i < 10; i++) {
const int seed = rd();
std::cout << "seed = " << seed << std::endl;
std::cout << "sortNet10: " << benchmark(sortNet10, seed).count() << std::endl;
std::cout << "sort: " << benchmark(sort, seed).count() << std::endl;
}
return 0;
}
与排序网络相比,我在无分支选择排序方面持续获得更好的结果。
$ gcc -v
gcc version 5.2.0 (GCC)
$ g++ -std=c++11 -Ofast sort.cpp && ./a.out
seed = -1727396418
sortNet10: 2.24137
sort: 2.21828
seed = 2003959850
sortNet10: 2.23914
sort: 2.21641
seed = 1994540383
sortNet10: 2.23782
sort: 2.21778
seed = 1258259982
sortNet10: 2.25199
sort: 2.21801
seed = 1821086932
sortNet10: 2.25535
sort: 2.2173
seed = 412262735
sortNet10: 2.24489
sort: 2.21776
seed = 1059795817
sortNet10: 2.29226
sort: 2.21777
seed = -188551272
sortNet10: 2.23803
sort: 2.22996
seed = 1043757247
sortNet10: 2.2503
sort: 2.23604
seed = -268332483
sortNet10: 2.24455
sort: 2.24304
for ( ; i<10; i++) (m > a[i]) && (m = a[i], indx = i ); 受到了特别良好的优化,否则它是有分支的(短路通常被视为一种分支)。 - examplefor (int n = 0; n<10; n++) a[n]=g(); 替换 std::shuffle。执行时间减半,网络现在更快了。 - DarioPstd::sort,但它的性能太差了,以至于我甚至没有将其包含在基准测试中。我猜对于小数据集来说,存在相当大的开销。 - DarioP如果FPGA在每个时钟转换时以数百兆赫的速度操作,则可以输出十个32位数字。操作开始时会有短暂延迟,因为数据填满了处理管道。之后,您应该能够每个时钟获得一个结果。或者,如果处理可以通过复制排序和分析管道进行并行化,则可以获得更多结果。原则上,解决方案几乎是微不足道的。
关键是:如果应用程序不受PC限制,并且数据流和处理与FPGA解决方案(作为独立或协处理器卡)“兼容”,则无论算法如何,您都无法击败可实现的性能水平使用任何语言编写的软件。
我只是进行了快速搜索,并找到了一篇可能对您有用的论文。看起来它可以追溯到2012年。今天(甚至当时),您可以在性能方面取得更好的表现。这就是链接:
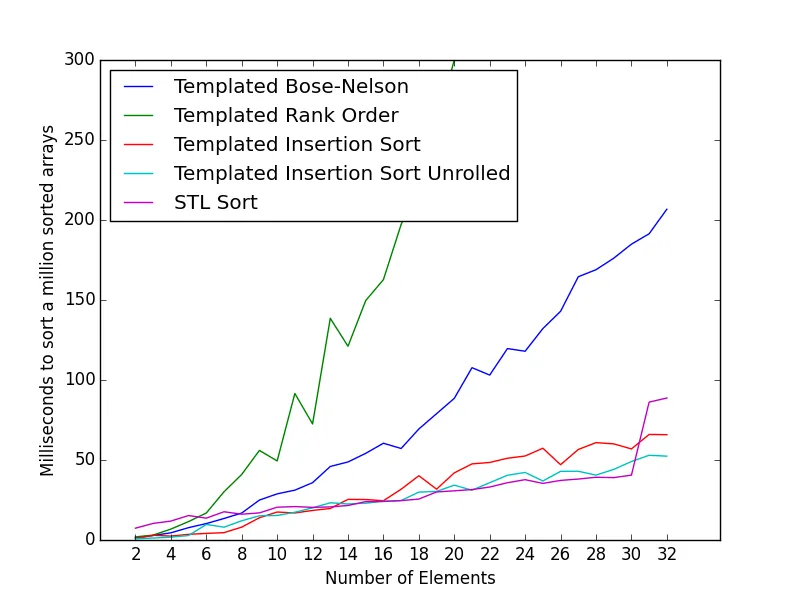
我最近写了一个小型课程,使用 Bose-Nelson 算法在编译时生成排序网络。
它可以用于创建一个非常快速的排序算法,适用于10个数字的排序。
/**
* A Functor class to create a sort for fixed sized arrays/containers with a
* compile time generated Bose-Nelson sorting network.
* \tparam NumElements The number of elements in the array or container to sort.
* \tparam T The element type.
* \tparam Compare A comparator functor class that returns true if lhs < rhs.
*/
template <unsigned NumElements, class Compare = void> class StaticSort
{
template <class A, class C> struct Swap
{
template <class T> inline void s(T &v0, T &v1)
{
T t = Compare()(v0, v1) ? v0 : v1; // Min
v1 = Compare()(v0, v1) ? v1 : v0; // Max
v0 = t;
}
inline Swap(A &a, const int &i0, const int &i1) { s(a[i0], a[i1]); }
};
template <class A> struct Swap <A, void>
{
template <class T> inline void s(T &v0, T &v1)
{
// Explicitly code out the Min and Max to nudge the compiler
// to generate branchless code.
T t = v0 < v1 ? v0 : v1; // Min
v1 = v0 < v1 ? v1 : v0; // Max
v0 = t;
}
inline Swap(A &a, const int &i0, const int &i1) { s(a[i0], a[i1]); }
};
template <class A, class C, int I, int J, int X, int Y> struct PB
{
inline PB(A &a)
{
enum { L = X >> 1, M = (X & 1 ? Y : Y + 1) >> 1, IAddL = I + L, XSubL = X - L };
PB<A, C, I, J, L, M> p0(a);
PB<A, C, IAddL, J + M, XSubL, Y - M> p1(a);
PB<A, C, IAddL, J, XSubL, M> p2(a);
}
};
template <class A, class C, int I, int J> struct PB <A, C, I, J, 1, 1>
{
inline PB(A &a) { Swap<A, C> s(a, I - 1, J - 1); }
};
template <class A, class C, int I, int J> struct PB <A, C, I, J, 1, 2>
{
inline PB(A &a) { Swap<A, C> s0(a, I - 1, J); Swap<A, C> s1(a, I - 1, J - 1); }
};
template <class A, class C, int I, int J> struct PB <A, C, I, J, 2, 1>
{
inline PB(A &a) { Swap<A, C> s0(a, I - 1, J - 1); Swap<A, C> s1(a, I, J - 1); }
};
template <class A, class C, int I, int M, bool Stop = false> struct PS
{
inline PS(A &a)
{
enum { L = M >> 1, IAddL = I + L, MSubL = M - L};
PS<A, C, I, L, (L <= 1)> ps0(a);
PS<A, C, IAddL, MSubL, (MSubL <= 1)> ps1(a);
PB<A, C, I, IAddL, L, MSubL> pb(a);
}
};
template <class A, class C, int I, int M> struct PS <A, C, I, M, true>
{
inline PS(A &a) {}
};
public:
/**
* Sorts the array/container arr.
* \param arr The array/container to be sorted.
*/
template <class Container> inline void operator() (Container &arr) const
{
PS<Container, Compare, 1, NumElements, (NumElements <= 1)> ps(arr);
};
/**
* Sorts the array arr.
* \param arr The array to be sorted.
*/
template <class T> inline void operator() (T *arr) const
{
PS<T*, Compare, 1, NumElements, (NumElements <= 1)> ps(arr);
};
};
#include <iostream>
#include <vector>
int main(int argc, const char * argv[])
{
enum { NumValues = 10 };
// Arrays
{
int rands[NumValues];
for (int i = 0; i < NumValues; ++i) rands[i] = rand() % 100;
std::cout << "Before Sort: \t";
for (int i = 0; i < NumValues; ++i) std::cout << rands[i] << " ";
std::cout << "\n";
StaticSort<NumValues> staticSort;
staticSort(rands);
std::cout << "After Sort: \t";
for (int i = 0; i < NumValues; ++i) std::cout << rands[i] << " ";
std::cout << "\n";
}
std::cout << "\n";
// STL Vector
{
std::vector<int> rands(NumValues);
for (int i = 0; i < NumValues; ++i) rands[i] = rand() % 100;
std::cout << "Before Sort: \t";
for (int i = 0; i < NumValues; ++i) std::cout << rands[i] << " ";
std::cout << "\n";
StaticSort<NumValues> staticSort;
staticSort(rands);
std::cout << "After Sort: \t";
for (int i = 0; i < NumValues; ++i) std::cout << rands[i] << " ";
std::cout << "\n";
}
return 0;
}
if(compare)swap语句。这样做是为了帮助编译器使用无分支代码。clang -O3编译并在我的2012年中期 MacBook Air上运行的。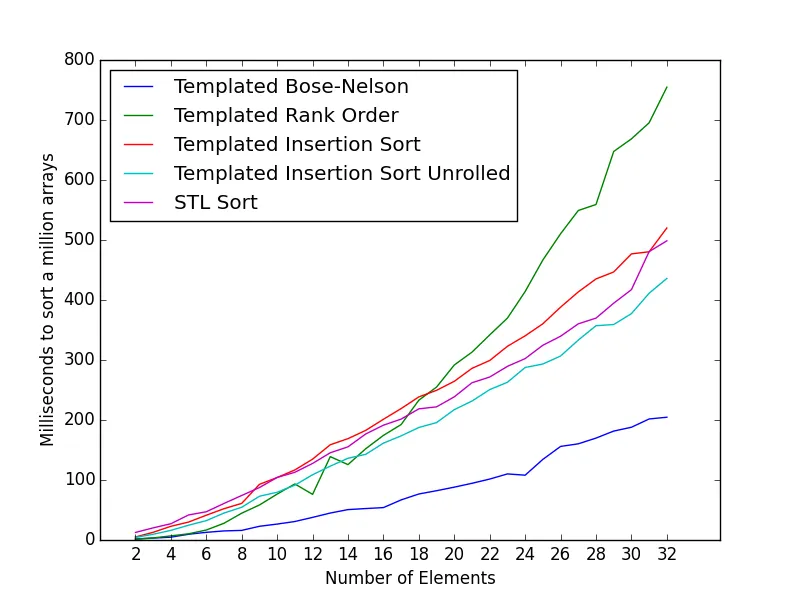
感谢Glenn Teitelbaum提供的未卷起插入排序算法。
以下是小型数组(6个元素)每次排序的平均时钟数。基准测试代码和示例可以在此问题中找到:
Direct call to qsort library function : 326.81
Naive implementation (insertion sort) : 132.98
Insertion Sort (Daniel Stutzbach) : 104.04
Insertion Sort Unrolled : 99.64
Insertion Sort Unrolled (Glenn Teitelbaum) : 81.55
Rank Order : 44.01
Rank Order with registers : 42.40
Sorting Networks (Daniel Stutzbach) : 88.06
Sorting Networks (Paul R) : 31.64
Sorting Networks 12 with Fast Swap : 29.68
Sorting Networks 12 reordered Swap : 28.61
Reordered Sorting Network w/ fast swap : 24.63
Templated Sorting Network (this class) : 25.37
v1 = v0 < v1 ? v1 : v0; // Max 仍然可能分支,这种情况下可以用 v1 += v0 - t 替换它,因为如果 t 是 v0,那么 v1 + v0 -t == v1 + v0 - v0 == v1,否则 t 是 v1,那么 v1 + v0 -t == v1 + v0 - v1 == v0。 - Glenn Teitelbaummaxss或minss指令。但是在不能使用时,可以使用其他方式进行交换。 :) - Vectorized{
final int a=in[0]<in[1]?in[0]:in[1];
final int b=in[0]<in[1]?in[1]:in[0];
in[0]=a;
in[1]=b;
}
for(int x=2;x<10;x+=2)
{
final int a=in[x]<in[x+1]?in[x]:in[x+1];
final int b=in[x]<in[x+1]?in[x+1]:in[x];
int y= x-1;
while(y>=0&&in[y]>b)
{
in[y+2]= in[y];
--y;
}
in[y+2]=b;
while(y>=0&&in[y]>a)
{
in[y+1]= in[y];
--y;
}
in[y+1]=a;
}
template <class T, int NUM>
class insert_sort;
template <class T>
class insert_sort<T,0>
// Stop template recursion
// Sorting one item is a no operation
{
public:
static void place(T *x) {}
static void sort(T * x) {}
};
template <class T, int NUM>
class insert_sort
// Use template recursion to do insertion sort.
// NUM is the index of the last item, e.g. for x[10] call <9>
{
public:
static void place(T *x)
{
T t1=x[NUM-1];
T t2=x[NUM];
if (t1 > t2)
{
x[NUM-1]=t2;
x[NUM]=t1;
insert_sort<T,NUM-1>::place(x);
}
}
static void sort(T * x)
{
insert_sort<T,NUM-1>::sort(x); // Sort everything before
place(x); // Put this item in
}
};
template<class IterType>
inline void sort10_iterator(IterType it)
{
#define SORT2(x,y) {if(data##x>data##y)std::swap(data##x,data##y);}
#define DD1(a) auto data##a=*(data+a);
#define DD2(a,b) auto data##a=*(data+a), data##b=*(data+b);
#define CB1(a) *(data+a)=data##a;
#define CB2(a,b) *(data+a)=data##a;*(data+b)=data##b;
DD2(1,4) SORT2(1,4) DD2(7,8) SORT2(7,8) DD2(2,3) SORT2(2,3) DD2(5,6) SORT2(5,6) DD2(0,9) SORT2(0,9)
SORT2(2,5) SORT2(0,7) SORT2(8,9) SORT2(3,6)
SORT2(4,9) SORT2(0,1)
SORT2(0,2) CB1(0) SORT2(6,9) CB1(9) SORT2(3,5) SORT2(4,7) SORT2(1,8)
SORT2(3,4) SORT2(5,8) SORT2(6,7) SORT2(1,2)
SORT2(7,8) CB1(8) SORT2(1,3) CB1(1) SORT2(2,5) SORT2(4,6)
SORT2(2,3) CB1(2) SORT2(6,7) CB1(7) SORT2(4,5)
SORT2(3,4) CB2(3,4) SORT2(5,6) CB2(5,6)
#undef CB1
#undef CB2
#undef DD1
#undef DD2
#undef SORT2
}
std::vector迭代器或其他随机访问迭代器来调用它。sort10_iterator(my_std_vector.begin());
插入排序平均需要29.6次比较才能对10个输入进行排序,最好的情况是9次比较,最坏的情况是45次比较(给定一个反向排序的输入)。
使用{9,6,1}希尔排序平均需要25.5次比较来对10个输入进行排序。最佳情况下需要14次比较,最坏情况下需要34次比较,对于反向排序的输入需要22次比较。
因此,使用希尔排序而不是插入排序可以将平均情况减少14%。虽然最佳情况增加了56%,但最坏情况减少了24%,这在需要保持最坏情况性能的应用程序中非常重要。反向情况减少了51%。
由于您似乎熟悉插入排序,因此可以将算法实现为{9,6}的排序网络,然后再添加插入排序({1}):
i[0] with i[9] // {9}
i[0] with i[6] // {6}
i[1] with i[7] // {6}
i[2] with i[8] // {6}
i[3] with i[9] // {6}
i[0 ... 9] // insertion sort