我希望增加缓冲区中的语音数据音量。问题在于我正在使用DirectSound,有一个主缓冲区和一个次要缓冲区——所有流的混合都是手动完成的。在语音聊天中,所有参与者都可以拥有独立的音量级别。我将每个流数据乘以一个值(增益),并将其总和添加到一个缓冲区中。一切都很好,但当我尝试将数据乘以大于1.0f的值时,会听到一些剪辑或其他奇怪的声音。
我尝试使用Audacity效果压缩器,但这并没有帮助减少奇怪的噪音。
也许我应该以其他方式修改增益?还是只需使用另一种后处理算法?
更新:哇,我刚发现了有趣的事情!我在增加音量之前和之后转储了音频。
这里是图片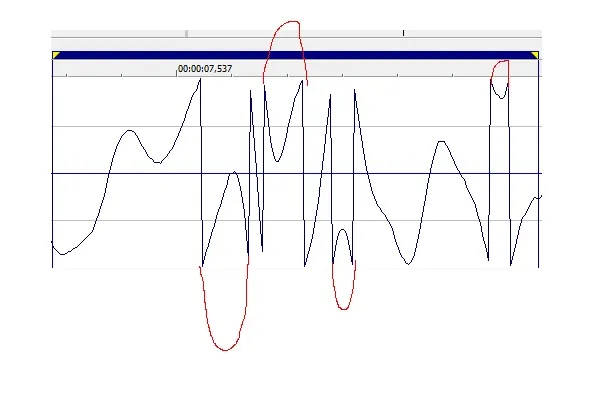 抱歉质量不高——我认为这就是声音应该出现的样子(我自己画了红线)。看起来真的像值超过了采样数据类型。但我无法理解为什么?我的样本缓冲区是BYTE,但我只通过short指针访问它。它是有符号的,但即使*ptr约为15-20千,剪辑也会发生。
抱歉质量不高——我认为这就是声音应该出现的样子(我自己画了红线)。看起来真的像值超过了采样数据类型。但我无法理解为什么?我的样本缓冲区是BYTE,但我只通过short指针访问它。它是有符号的,但即使*ptr约为15-20千,剪辑也会发生。
我尝试使用Audacity效果压缩器,但这并没有帮助减少奇怪的噪音。
也许我应该以其他方式修改增益?还是只需使用另一种后处理算法?
更新:哇,我刚发现了有趣的事情!我在增加音量之前和之后转储了音频。
这里是图片
抱歉质量不高——我认为这就是声音应该出现的样子(我自己画了红线)。看起来真的像值超过了采样数据类型。但我无法理解为什么?我的样本缓冲区是BYTE,但我只通过short指针访问它。它是有符号的,但即使*ptr约为15-20千,剪辑也会发生。