背景:我正试图使用this approach实现一个基于时间序列的版本化数据库,使用gremlin(tinkerpop v3)。
但是,正如你所看到的,我必须列出“状态”节点的属性 - 在上面的示例中,产品的名称和价格属性。但这将适用于任何域对象,因此我不想总是列出属性。我可以在此之前运行查询以获取属性,但我认为我不应该需要运行两个查询,并且有两个往返的开销。我已经查看了“聚合”,“联合”,“折叠”等等,但似乎没有做到这一点的东西。
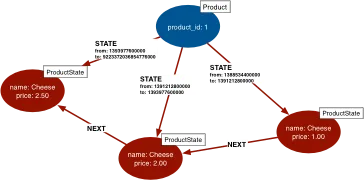
:> g.V().hasLabel('product').
as('cid').
outE('state').
has('to', 8640000000000000).
inV().
as('name').
as('price').
select('cid', 'name','price').
by('cid').
by('name').
by('price')
=>{cid=1, name="Cheese", price=2.50}
=>{cid=2, name="Ham", price=5.00}
但是,正如你所看到的,我必须列出“状态”节点的属性 - 在上面的示例中,产品的名称和价格属性。但这将适用于任何域对象,因此我不想总是列出属性。我可以在此之前运行查询以获取属性,但我认为我不应该需要运行两个查询,并且有两个往返的开销。我已经查看了“聚合”,“联合”,“折叠”等等,但似乎没有做到这一点的东西。
有什么想法吗?
===================
编辑: 基于Daniel的回答(目前还不完全符合我的要求),我将使用他的示例图表。在'modernGraph'中,人们创建->软件。如果我运行:
> g.V().hasLabel('person').valueMap()
==>[name:[marko], age:[29]]
==>[name:[vadas], age:[27]]
==>[name:[josh], age:[32]]
==>[name:[peter], age:[35]]
然后结果是一系列带有属性的实体列表。我的目标是,假设一个人只能创建一个软件(尽管希望我们稍后可以看到如何为创建的软件列表打开此功能),将创建的软件“语言”属性包含在返回的实体中,以获得:
> <run some query here>
==>[name:[marko], age:[29], lang:[java]]
==>[name:[vadas], age:[27], lang:[java]]
==>[name:[josh], age:[32], lang:[java]]
==>[name:[peter], age:[35], lang:[java]]
目前,到目前为止最好的建议如下:
> g.V().hasLabel('person').union(identity(), out("created")).valueMap().unfold().group().by {it.getKey()}.by {it.getValue()}
==>[name:[marko, lop, lop, lop, vadas, josh, ripple, peter], lang:[java, java, java, java], age:[29, 27, 32, 35]]
我希望这更清晰。如果不是,请告诉我。
.mapKeys()和.mapValues(),尝试使用它们。 - Daniel Kuppitz