我有一个road_events表:
create table road_events (
event_id number(4,0),
road_id number(4,0),
year number(4,0),
from_meas number(10,2),
to_meas number(10,2),
total_road_length number(10,2)
);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (1,1,2020,25,50,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (2,1,2000,25,50,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (3,1,1980,0,25,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (4,1,1960,75,100,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (5,1,1940,1,100,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (6,2,2000,10,30,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (7,2,1975,30,60,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (8,2,1950,50,90,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (9,3,2050,40,90,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (10,4,2040,0,200,200);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (11,4,2013,0,199,200);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (12,4,2001,0,200,200);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (13,5,1985,50,70,300);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (14,5,1985,10,50,300);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (15,5,1965,1,301,300);
commit;
select * from road_events;
EVENT_ID ROAD_ID YEAR FROM_MEAS TO_MEAS TOTAL_ROAD_LENGTH
---------- ---------- ---------- ---------- ---------- -----------------
1 1 2020 25 50 100
2 1 2000 25 50 100
3 1 1980 0 25 100
4 1 1960 75 100 100
5 1 1940 1 100 100
6 2 2000 10 30 100
7 2 1975 30 60 100
8 2 1950 50 90 100
9 3 2050 40 90 100
10 4 2040 0 200 200
11 4 2013 0 199 200
12 4 2001 0 200 200
13 5 1985 50 70 300
14 5 1985 10 50 300
15 5 1965 1 301 300
我想选择每条道路上代表最近工作的事件。
这是一项棘手的操作,因为这些事件通常只与道路的一部分相关。这意味着我不能简单地选择每条道路上最近的事件;我需要仅选择最近的事件里程数而不重叠。
可能的逻辑(按顺序):
我不想猜测如何解决这个问题,因为它可能会带来更多的伤害而不是帮助(有点像XY Problem)。另一方面,它可能会提供关于问题本质的见解,所以我们来试试:
1. 选择每条道路最近的事件。我们将称最近的事件为:`事件A`。 2. 如果`事件A >= 总道路长度`,那么这就是我需要的全部内容。算法到此结束。 3. 否则,获取下一个时间顺序(`事件B`),其范围与`事件A`不同。 4. 如果`事件B`的范围重叠`事件A`的范围,则仅获取不重叠的部分。 5. 重复步骤3和4,直到总事件长度`= 总道路长度`。或者当该道路没有更多事件时停止。
问题:
我知道这是一个很高的要求,但要做到这一点需要什么?
这是一个经典的线性参考问题。如果我能在查询中执行线性参考操作,那将非常有帮助。
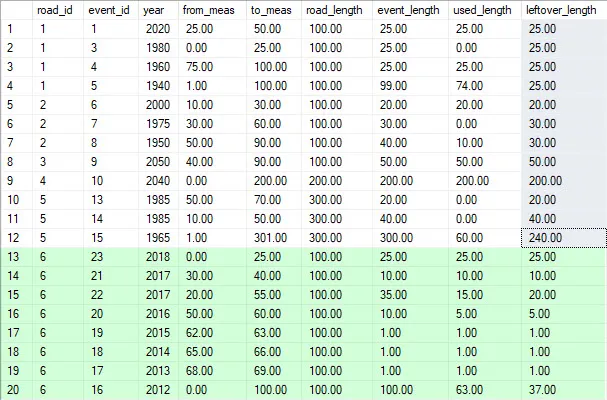
结果将是:
EVENT_ID ROAD_ID YEAR TOTAL_ROAD_LENGTH EVENT_LENGTH
---------- ---------- ---------- ----------------- ------------
1 1 2020 100 25
3 1 1980 100 25
4 1 1960 100 25
5 1 1940 100 25
6 2 2000 100 20
7 2 1975 100 30
8 2 1950 100 30
9 3 2050 100 50
10 4 2040 200 200
13 5 1985 300 20
14 5 1985 300 40
15 5 1965 300 240
相关问题: 选择不重叠的数字范围
选项1(dnoeth的选项):返回3行就可以了;这是最明确的选项。选项2:然而,事后看来,我认为没有必要在查询中返回from_meas和to_meas。但是,知道返回的事件长度是必要的。因此,我们可以只返回一个event_length列,它将是10-20/2010和40-100/2010的聚合。当然,还有一个20-40/2020的行。 - User1974