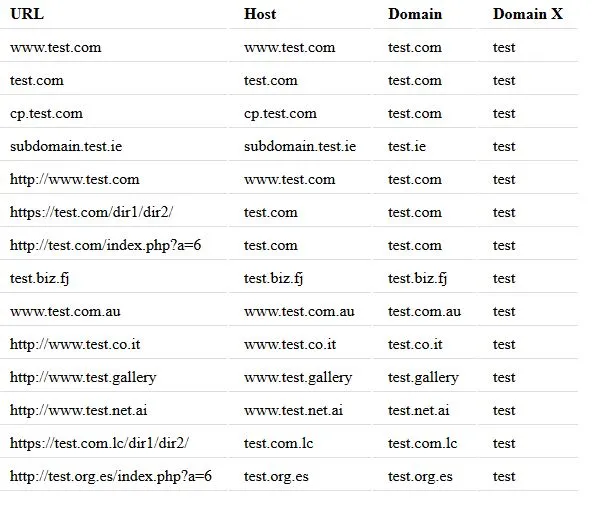
基本上,您想要的是:
google.com -> google.com -> google
www.google.com -> google.com -> google
google.co.uk -> google.co.uk -> google
www.google.co.uk -> google.co.uk -> google
www.google.org -> google.org -> google
www.google.org.uk -> google.org.uk -> google
可选:
www.google.com -> google.com -> www.google
images.google.com -> google.com -> images.google
mail.yahoo.co.uk -> yahoo.co.uk -> mail.yahoo
mail.yahoo.com -> yahoo.com -> mail.yahoo
www.mail.yahoo.com -> yahoo.com -> mail.yahoo
您不需要构建一个随时变化的正则表达式,只需查看名称的倒数第二部分,即可正确匹配99%的域名。
(co|com|gov|net|org)
如果是这些之一,则需要匹配3个点,否则需要匹配2个点。简单吧。现在,我的正则表达式技巧不如其他SO用户的高超,所以我发现实现这一点的最佳方法是使用一些代码,假设您已经去掉了路径:
my @d=split /\./,$domain; # split the domain part into an array
$c=@d; # count how many parts
$dest=$d[$c-2].'.'.$d[$c-1]; # use the last 2 parts
if ($d[$c-2]=~m/(co|com|gov|net|org)/) { # is the second-last part one of these?
$dest=$d[$c-3].'.'.$dest; # if so, add a third part
};
print $dest; # show it
根据您的问题,如果只需要获取名称:
my @d=split /\./,$domain; # split the domain part into an array
$c=@d; # count how many parts
if ($d[$c-2]=~m/(co|com|gov|net|org)/) { # is the second-last part one of these?
$dest=$d[$c-3]; # if so, give the third last
$dest=$d[$c-4].'.'.$dest if ($c>3); # optional bit
} else {
$dest=$d[$c-2]; # else the second last
$dest=$d[$c-3].'.'.$dest if ($c>2); # optional bit
};
print $dest; # show it
我喜欢这种方法是因为它是无需维护的。除非您想验证它是否是合法域名,但这有点毫无意义,因为您很可能只使用它来处理日志文件,而无效的域名不会首先出现在其中。
如果您想匹配"非官方"子域名,例如bozo.za.net、bozo.au.uk、bozo.msf.ru,只需将(za|au|msf)添加到正则表达式中即可。
我很想看到有人仅使用正则表达式完成所有这些操作,我相信这是可能的。
http://en.wikipedia.org/wiki/URL,该URL中的域名是en.wikipedia.org。 - Thanatos