进一步阐述我之前的建议和@Alexandr Shurigin提出的有趣解决方案,现在我提出另一个选项。
这个新方案将“签名”分成两个字段:
- code:一个可变长度的字母数字字符串
- weight:一个数值,可能带有前导0需要忽略
给定:
[
'X 1',
'XY 1',
'XYZ 1',
'BA 1',
'BA 10',
'BA 100',
'BA 2',
'BA 1002',
'BA 1000',
'BA 1001',
'BA 003',
]
预期结果是:
[
'BA 1',
'BA 2',
'BA 003',
'BA 10',
'BA 100',
'BA 1000',
'BA 1001',
'BA 1002',
'X 1',
'XY 1',
'XYZ 1',
]
所有计算都以通用的方式委托给数据库,这要归功于django.db.models.functions模块。
queryset = (
Item.objects.annotate(
split_index=StrIndex('signature', Value(' ')),
).annotate(
left=Substr('signature', Value(1), 'split_index', output_field=CharField()),
right=Substr('signature', F('split_index'), output_field=CharField()),
).annotate(
code=Trim('left'),
weight=Cast('right', output_field=IntegerField())
).order_by('code', 'weight')
)
更加简洁但可读性较差的解决方案如下:
queryset = (
Item.objects.annotate(
split_index=StrIndex('signature', Value(' ')),
).annotate(
code=Trim(Substr('signature', Value(1), 'split_index', output_field=CharField())),
weight=Cast(Substr('signature', F('split_index'), output_field=CharField()), output_field=IntegerField())
).order_by('code', 'weight')
)
我真正需要的是一个“IndexOf”函数来计算“split_index”,作为第一个空格或数字的位置,从而实现真正的自然排序行为(例如接受“BA123”和“BA 123”)。
证明:
import django
from pprint import pprint
from backend.models import Item
from django.db.models.functions import Length, StrIndex, Substr, Cast, Trim
from django.db.models import Value, F, CharField, IntegerField
class ModelsItemCase(django.test.TransactionTestCase):
def test_item_sorting(self):
signatures = [
'X 1',
'XY 1',
'XYZ 1',
'BA 1',
'BA 10',
'BA 100',
'BA 2',
'BA 1002',
'BA 1000',
'BA 1001',
'BA 003',
]
for signature in signatures:
Item.objects.create(signature=signature)
print(' ')
pprint(list(Item.objects.all()))
print('')
expected_result = [
'BA 1',
'BA 2',
'BA 003',
'BA 10',
'BA 100',
'BA 1000',
'BA 1001',
'BA 1002',
'X 1',
'XY 1',
'XYZ 1',
]
queryset = (
Item.objects.annotate(
split_index=StrIndex('signature', Value(' ')),
).annotate(
code=Trim(Substr('signature', Value(1), 'split_index', output_field=CharField())),
weight=Cast(Substr('signature', F('split_index'), output_field=CharField()), output_field=IntegerField())
).order_by('code', 'weight')
)
pprint(list(queryset))
print(' ')
print(str(queryset.query))
self.assertSequenceEqual(
[row.signature for row in queryset],
expected_result
)
对于sqlite3,生成的查询语句如下:
SELECT
"backend_item"."id",
"backend_item"."signature",
INSTR("backend_item"."signature", ) AS "split_index",
TRIM(SUBSTR("backend_item"."signature", 1, INSTR("backend_item"."signature", ))) AS "code",
CAST(SUBSTR("backend_item"."signature", INSTR("backend_item"."signature", )) AS integer) AS "weight"
FROM "backend_item"
ORDER BY "code" ASC, "weight" ASC
而对于PostgreSQL:
SELECT
"backend_item"."id",
"backend_item"."signature",
STRPOS("backend_item"."signature", ) AS "split_index",
TRIM(SUBSTRING("backend_item"."signature", 1, STRPOS("backend_item"."signature", ))) AS "code",
(SUBSTRING("backend_item"."signature", STRPOS("backend_item"."signature", )))::integer AS "weight"
FROM "backend_item"
ORDER BY "code" ASC, "weight" ASC
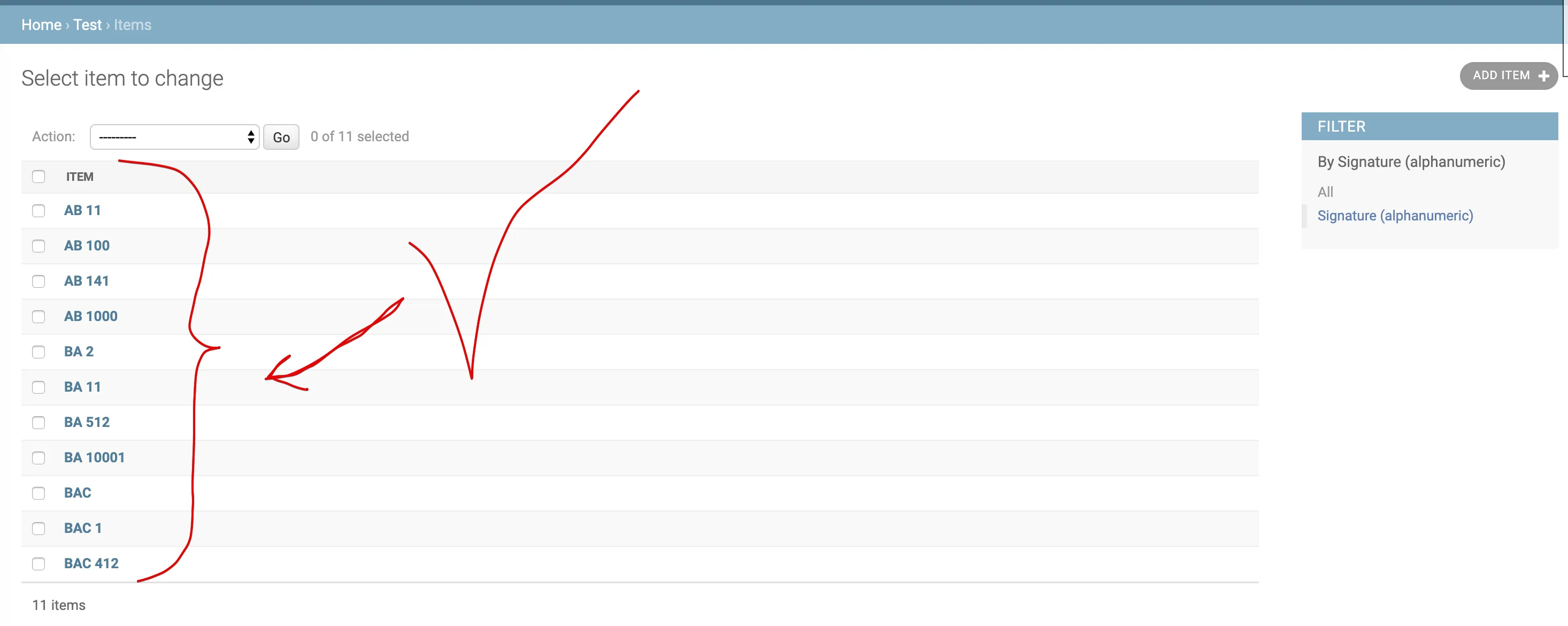
 我期望得到的是一个类似于
我期望得到的是一个类似于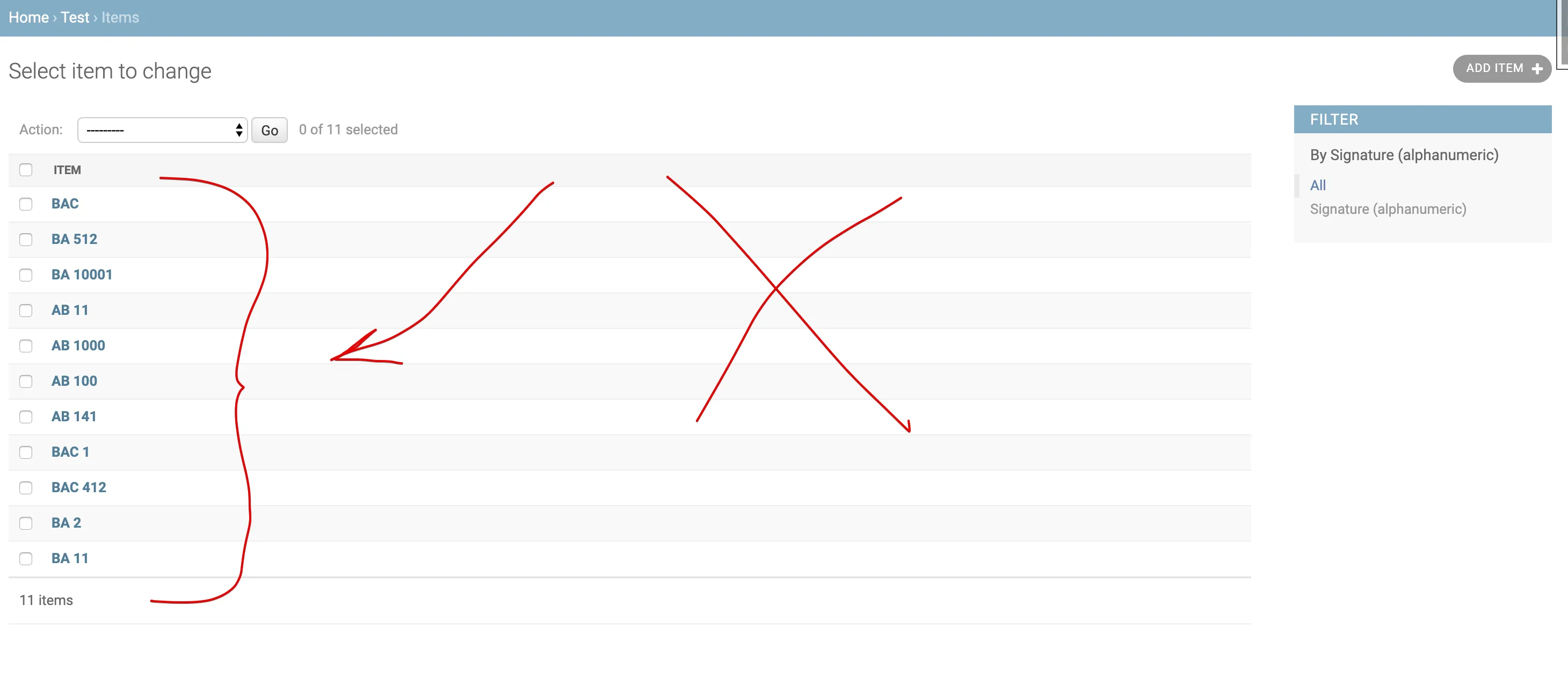
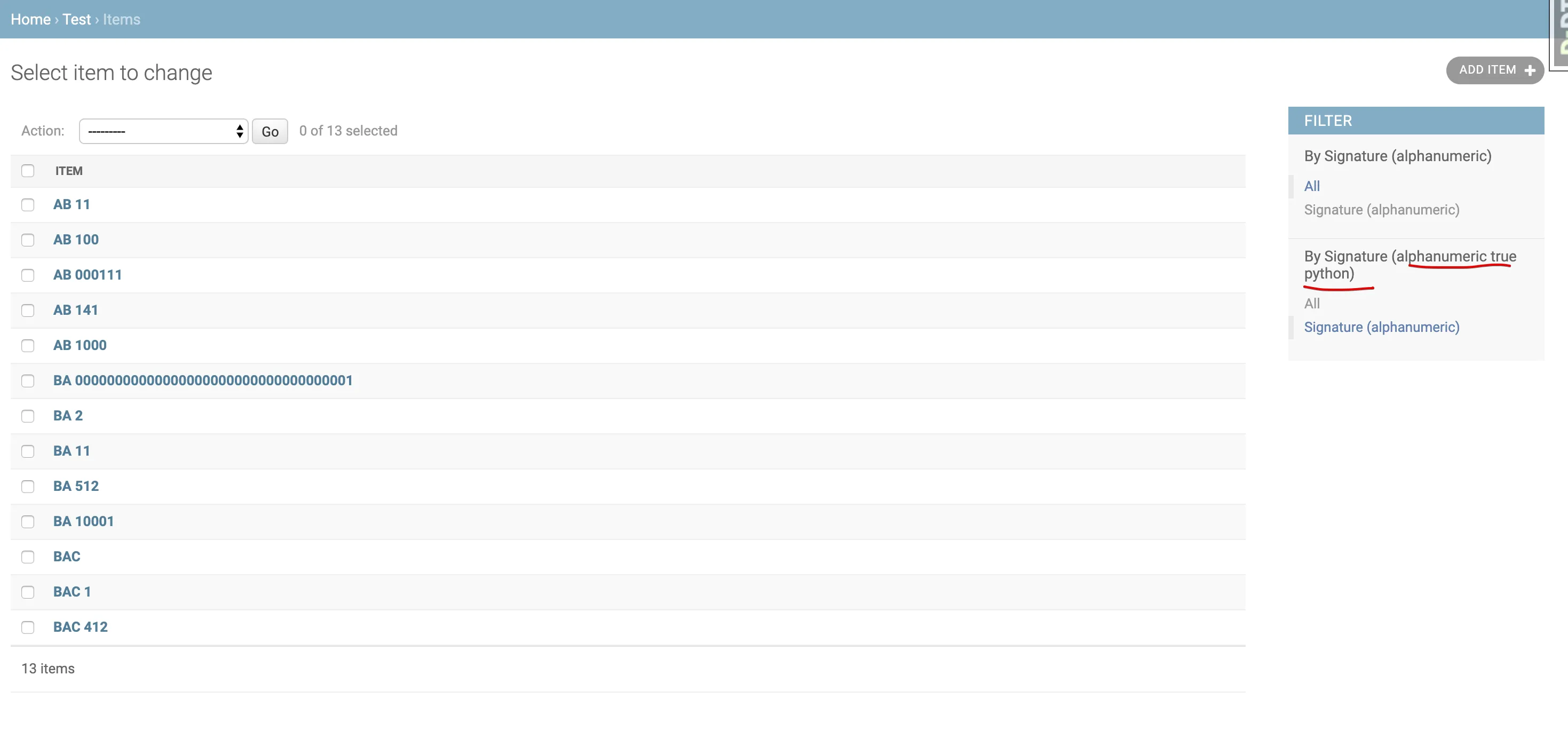
BA 0001,BA 0010,BA 30,像natsort这样的库可以正确排序。 - Oskar Persson(.*)\D(?:0*)(?!$)(\d*)$,您可以将前缀和后缀作为单独的组获取:https://regex101.com/r/iasgsz/1 - Oskar Persson