个体序列的压缩极限
一个序列的压缩极限是什么意思?
对于这个问题可以给出两个答案:
一个序列的压缩极限是一个未解决的问题。此外,已经证明这个极限是无法计算的。
香农定义了一个与实际相关性很大的子问题,在这个子问题中可以定义一个理论上的极限(源编码定理)。这个子问题是纯粹概率性的,被称为源编码。
信息传输问题在其最一般形式下的定义
要理解这两个答案,必须介绍信息传输问题在其最一般形式下的问题。为了在两个点之间进行信息传输,两个主体必须共享一种通信语言。这个要求是必要的,没有通信语言,传输的消息就无法理解,因此也不携带任何信息。因此,信息传输问题在其最一般形式下研究的是在共享通信语言的两个点之间以任何形式传输信息。
这个定义的问题在于“以任何形式的信息”这个概念在数学上很难形式化。因此,有必要首先简化问题,将信息定义为一个数字序列。通过这种方式,得到了一个子问题,其中信息的概念是明确定义的,并且可以从数学角度进行形式化。
因此,传递信息所需的两个要素是:携带信息的压缩序列和编码器和解码器都熟知的通信语言。
压缩序列:表示从要传输的序列中获得的任何信息。从实际角度来看,从序列中获取的对解码器恢复原始消息有用的任何信息都应被视为压缩消息的一部分。
通信语言:表示一组规则,允许两个主体之间进行通信,从而实现信息的传递。从实际角度来看,生成消息之前存在的任何信息都可以被视为通信语言的一部分。
源编码
在他著名的文章《通信的数学理论》中,香农引入了对信息传输问题的进一步修改,从而使他能够得到一个子问题,可以在其中定义理论压缩极限。为此,香农引入了生成消息的源。此外,将符号转换为编码字的编码方案是根据源的信息而不是从消息中获取的信息生成的。因此,在生成消息之前定义编码方案可以被视为通信语言的一个组成部分。然后,香农形式化了信息的概念,为此他开发了一个变量,可以唯一地定义在编码方案存在的情况下传输的消息。香农提出的解决方案是将信息视为变异的度量。执行此测量的生成函数称为熵H。以下这句话摘自《通信的数学理论》一文,让我们理解了香农对熵的概念。
“在一个概率为1(确定性)且其他所有概率为零(不可能性)的极限情况下,熵为零(完全没有不确定性-没有选择的自由-没有信息)。
关于他所定义的子问题,香农设法通过发展源编码定理来定义一个理论压缩极限。该定理证明了熵定义了替代压缩消息中符号的平均最小长度。因此,给定一个由随机变量i.i.d.生成长度为N的消息的源X,压缩消息的长度不能超过NH(X)。在消息生成之前定义的编码方案不是压缩消息的一部分。
当源未知时,可以应用Shannon所发展的理论。在这种情况下,可以计算零阶经验熵H0(m),其中频率是从要传输的消息m中获取的。在这种情况下,使用序列中符号的频率,在生成消息后开发编码方案,因此它必须成为压缩消息的一部分。因此,压缩消息由NH0(M)+编码方案定义。由于H0(m)的值非常接近H(X)的值,编码方案代表了冗余,也称为熵编码的低效性。
实际上,生成消息的源的不可知性确定了压缩消息中的冗余存在。此外,编码方案的长度取决于所使用的语言,因此无法精确定义。因此,无法定义压缩消息的长度限制。因此,使用Shannon引入的形式主义,我们已经证明了源未知的序列的压缩极限是不可计算的。
源熵H(X)和零阶经验熵H0(m)之间的区别
NH(X)的值代表了压缩后的消息。因此,熵在这种情况下更广义地定义了消息的信息,而不仅仅是香农信息。不幸的是,这种方法并不能代表信息传输的一般情况,而只代表了编码器和解码器都知道生成消息的源的子问题。
NH0(m)的值并不代表压缩后的消息。因此,零阶经验熵仅代表单个符号的香农信息的平均值。因此,零阶经验熵的意义比源的熵要少得多。然而,在这种情况下,信息传输问题的处理方式比源编码的情况更加普遍。
为了证明刚才所说的,我们给出以下例子:让我们取一个随机变量i.i.d.的均匀源X,它生成长度为N的消息。当然,这个序列是无法压缩的。因此,平均而言,压缩后的消息长度必须大于或等于N。在第一种情况下,编码器和解码器都知道源,因此我们可以应用源编码。得到的结果是所有消息的长度为NH(X),由于H(X)=1(我们使用字母表的维度作为熵的基数),压缩后的消息长度为N。所以,在这种情况下,我们达到了理论上的压缩极限。在第二种情况下,编码器和解码器都不知道源。因此,编码器必须使用消息中符号频率的值来计算熵。这样,就得到了零阶经验熵H0(m)。源是均匀的,但只有少量生成的消息具有均匀的符号分布。因此,消息的零阶经验熵H0(m)的平均值将小于H(X)。因此,如果我们不将编码方案视为压缩消息的一部分,我们得到一个不合逻辑的结果,实际上,我们有NH0(m)信息论的现代方法
其中最重要的方面之一是了解源编码是最一般形式下的信息传输问题的子问题。因此,当源未知时,只能计算零阶经验熵,这个参数的价值比源熵受到更多限制。实际上,将零阶经验熵乘以消息长度NH0(m)得到的值并不代表压缩后的消息。在这种情况下,编码方案也必须包含在压缩的消息中,在生成消息后定义,因此不能包含在通信语言中。这种方法代表了一个重要的视角变化。事实上,即使源未知,仅将压缩的消息NH0(m)视为与源编码一样,在过去也是绝对正常的。
随着一种新理论的出现,改变视角变得必要,这种理论可以在字母表大于或等于3时应用,以减少源未知时产生的冗余。这个理论的目的是使编码序列NH0(m)和编码方案更有效地相互作用。
现在,我将解释这个理论的基础。如果我们需要对一个长度为N且字母表为A的序列进行熵编码,而我们并不知道其源头,我们唯一拥有的信息是该序列将是可能序列中的一部分,可能序列的数量为|A|^N。
因此,使用熵编码来改善压缩序列(编码序列+编码方案)的平均长度的唯一可能方式,就是将所有可能序列的集合转化为一个新的、由平均上可以在更少空间中进行压缩的序列组成的相同大小的集合。通过这种方式,即使我们不知道生成序列的源头,我们知道如果应用这种转化,我们可以平均获得比未经转化的序列的压缩消息更短的压缩消息。
具有这些特征的集合是由长度为N+K的序列组成的维度为|A|^N的集合。增加序列的长度也会增加包含所有可能序列的集合的大小,从而变为|A|^N+K。因此,从这个集合中可以选择一个大小为|A|^N的子集,其中包含具有零阶经验熵最小值的序列。
以这种方式,我们得到以下结果:给定由未知的随机变量i.i.d.源X生成的长度为N的消息m,应用描述的变换f(m),我们平均得到:
NH(X)<Avg(NtH0(f(m)+编码方案)<Avg(NH0(m)+编码方案)
其中Nt>N
Avg(NH0(m)+编码方案) = 编码序列m+编码方案的平均值
Avg(NtH0(f(m)+编码方案) = 编码转换序列f(m)+编码方案的平均值
NH(X)是未知的压缩限制,事实上,我们设置了源未知的条件。正如开头所提到的,当源未知时,在目前的知识状态下无法定义一个压缩限制。
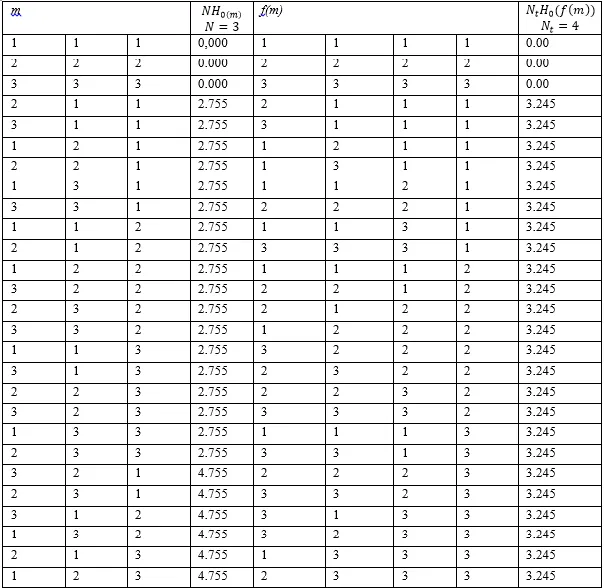
现在,我们通过实验证明了所得到的结果。让我们取一个长度为3且字母表为3的序列,可能的序列有27个。如果我们将长度增加到4并保持字母表为3,可能的序列变为81个。在这81个序列中,我们选择具有最小H0(m)值的27个。通过这种方式,两个集合具有相同数量的元素。因此,我们可以定义两个集合之间的一对一关系。下表显示了两个集合的27个元素。在第一列中,我们有消息m,在第二列中,我们有NH0(m),在第三列中,我们有转化后的消息f(m),在第四列中,我们有转化后的消息f(m)的NtH0(f(m))。
输入图像描述
零阶经验熵的平均值乘以消息m的字符串长度N=3为:
Avg(NH0(m))=2.893
其中N=3。
零阶经验熵乘以转换后的消息f(m)的字符串长度Nt=4的平均值为:
Avg(NtH0(f(m))=2.884
其中Nt=4。
因此,尽管转换后的消息更长,但平均而言,应用转换后零阶经验熵乘以消息长度的值较小。因此,即使我们不知道源数据,通过应用转换,我们平均而言可以获得零阶经验熵乘以消息长度值的减少。因此,编码消息的长度(符号被码字替代)减小。
现在,让我们来看一下编码方案,在这种情况下,进行评估更加困难,因为编码方案的长度取决于所使用的压缩方法。但是,从理论上讲,最影响编码方案长度的参数是字母表的大小。因此,我们计算两个集合中字母表A的平均大小。
在表格的第一列中,字母表大小|A|的平均值为:
Avg(|A|) = 2.1
在表格的第三列中,转换后的消息f(m)的字母表大小|A|的平均值为:
Avg(|A|) = 1.89
所得结果仅对报告的情况有效。实际上,无论字母表的大小如何,由较长序列组成的转换集始终具有比|A|少的符号数的类型类别更多。通过类型类别,我们指的是具有相同符号频率的字符串集合,例如,字符串113和字符串131实际上属于同一个类型类别,因为它们都具有符号频率1=2/3和3=1/4。
因此,平均而言,NH0(f(m)) < NH0(m)且编码方案f(m) < 编码方案m,我们通过实验证明了以下不等式:
NH(X) < Avg(NH0(f(m)+编码方案) < Avg(NtH0(m)+编码方案)
这样一来,经过转换的消息集合在使用熵编码时具有比未经转换的消息集合更小的平均压缩消息长度。因此,在源未知的情况下,如果应用所描述的转换,通常可以获得压缩消息的减少。因此,我们能够减少由于不知道源而导致的低效性。
总之,我们在开始时提出的关于序列最小压缩长度是否存在的问题,仍然是一个尚未解决的问题。然而,关于信息理论的新发展成功地减少了在不知道源的情况下产生的低效性,从而在这个领域取得了重要的进展。
{kind=link}