data.table 很笨重,但这是其中一种方法:
library(data.table)
DT <- data.table(mtcars)
rbind(
DT[,.(mean(disp)), by=.(cyl,carb)],
DT[,.(mean(disp), carb=NA), by=.(cyl) ],
DT[,.(mean(disp), cyl=NA), by=.(carb)]
)[order(cyl,carb)]
这提供了
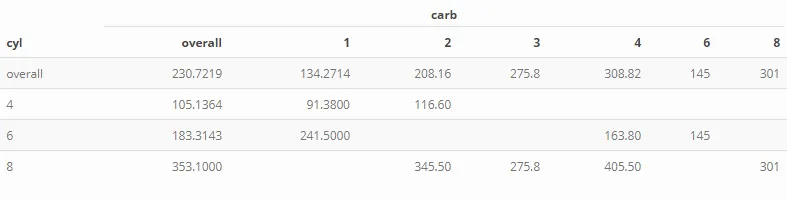
cyl carb V1
1: 4 1 91.3800
2: 4 2 116.6000
3: 4 NA 105.1364
4: 6 1 241.5000
5: 6 4 163.8000
6: 6 6 145.0000
7: 6 NA 183.3143
8: 8 2 345.5000
9: 8 3 275.8000
10: 8 4 405.5000
11: 8 8 301.0000
12: 8 NA 353.1000
13: NA 1 134.2714
14: NA 2 208.1600
15: NA 3 275.8000
16: NA 4 308.8200
17: NA 6 145.0000
18: NA 8 301.0000
我更愿意看到类似于R的table这样的结果,但不知道是否有相应的函数。
dplyr @akrun找到了类似的代码。
bind_rows(
mtcars %>%
group_by(cyl, carb) %>%
summarise(Mean= mean(disp)),
mtcars %>%
group_by(cyl) %>%
summarise(carb=NA, Mean=mean(disp)),
mtcars %>%
group_by(carb) %>%
summarise(cyl=NA, Mean=mean(disp))
) %>% arrange(cyl, carb)
我们可以将重复操作封装在一个函数中
library(lazyeval)
f1 <- function(df, grp, Var, func){
FUN <- match.fun(func)
df %>%
group_by_(.dots=grp) %>%
summarise_(interp(~FUN(v), v=as.name(Var)))
}
m1 <- f1(mtcars, c('carb', 'cyl'), 'disp', 'mean')
m2 <- f1(mtcars, 'carb', 'disp', 'mean')
m3 <- f1(mtcars, 'cyl', 'disp', 'mean')
bind_rows(list(m1, m2, m3)) %>%
arrange(cyl, carb) %>%
rename(Mean=`FUN(disp)`)
carb cyl Mean
1 1 4 91.3800
2 2 4 116.6000
3 NA 4 105.1364
4 1 6 241.5000
5 4 6 163.8000
6 6 6 145.0000
7 NA 6 183.3143
8 2 8 345.5000
9 3 8 275.8000
10 4 8 405.5000
11 8 8 301.0000
12 NA 8 353.1000
13 1 NA 134.2714
14 2 NA 208.1600
15 3 NA 275.8000
16 4 NA 308.8200
17 6 NA 145.0000
18 8 NA 301.0000
无论哪种选择,都可以使用 data.table 的
rbindlist 和
fill 使其稍微美观一些。
rbindlist(list(
mtcars %>% group_by(cyl) %>% summarise(mean(disp)),
mtcars %>% group_by(carb) %>% summarise(mean(disp)),
mtcars %>% group_by(cyl,carb) %>% summarise(mean(disp))
),fill=TRUE) %>% arrange(cyl,carb)
rbindlist(list(
DT[,mean(disp),by=.(cyl,carb)],
DT[,mean(disp),by=.(cyl)],
DT[,mean(disp),by=.(carb)]
),fill=TRUE)[order(cyl,carb)]
cummean()?我还是不明白这个问题。嗯,算了。 - C8H10N4O2