我使用SDL编写了一个模拟程序,显示了一个非常大的图块地图(约240 * 240个图块)。由于我对SDL库还比较陌生,因此我无法确定每秒渲染超过50,000个图块的相当缓慢的性能是否正常。每个图块始终可见,大约为4 * 4px。目前它正在每帧通过2D数组迭代并渲染每个单独的图块,这给我大约40fps,速度太慢,实际上无法在系统后添加任何游戏逻辑。
我尝试找到一些替代系统,例如仅更新已更新的图块,但人们总是评论说这是一种不好的做法,渲染器应该在每个帧中进行清理等等。
这里有地图的图片。
所以我想问一下是否有比每帧渲染每个单独图块更高效的系统呢?
这是我正在使用的简单渲染方法的编辑。
因此,在这个语境中,每个瓦片被称为“站点”,这是因为它们还存储诸如湿度、温度等信息。
在生成过程中,为每个站点分配了一个生物群系,每个生物群系基本上都是一个ID,每个陆地生物群系的ID都大于0,而每个水生ID都为0或更低。
这使得我可以将每个生物群系精灵按ID排序放入“biome_sprites.png”图像中。所有陆地精灵基本上都在第一行,而所有水域瓦片都在第二行。这样,我就不必手动为生物群系分配精灵,该方法可以通过将瓷砖大小(基本上是宽度)与生物群系相乘来自行完成。
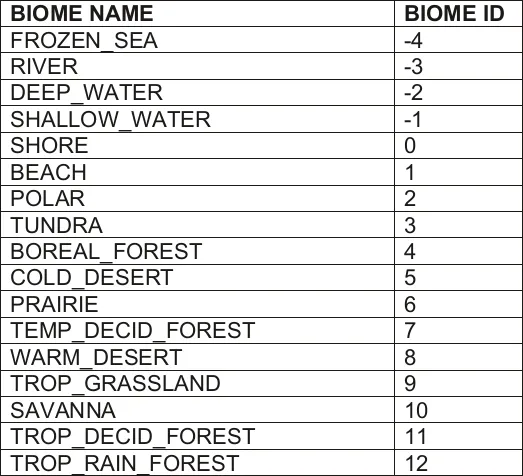
这是我的SDD/GDD中的生物群系ID表和实际的精灵表。
graphics类中的blitOnRenderer方法基本上只是运行一个SDL_RenderCopy将纹理复制到渲染器上。
在游戏循环中,每帧都会调用RenderClear和RenderPresent函数。
我真心希望我已经讲清楚了,如果有任何问题,请随时问,我是寻求帮助的人,所以我会尽力配合 :D
我尝试找到一些替代系统,例如仅更新已更新的图块,但人们总是评论说这是一种不好的做法,渲染器应该在每个帧中进行清理等等。
这里有地图的图片。
所以我想问一下是否有比每帧渲染每个单独图块更高效的系统呢?
这是我正在使用的简单渲染方法的编辑。
void World::DirtyBiomeDraw(Graphics *graphics) {
if(_biomeTexture == NULL) {
_biomeTexture = graphics->loadImage("assets/biome_sprites.png");
printf("Biome texture loaded.\n");
}
for(int i = 0; i < globals::WORLD_WIDTH; i++) {
for(int l = 0; l < globals::WORLD_HEIGHT; l++) {
SDL_Rect srect;
srect.h = globals::SPRITE_SIZE;
srect.w = globals::SPRITE_SIZE;
if(sites[l][i].biome > 0) {
srect.y = 0;
srect.x = (globals::SPRITE_SIZE * sites[l][i].biome) - globals::SPRITE_SIZE;
}
else {
srect.y = globals::SPRITE_SIZE;
srect.x = globals::SPRITE_SIZE * fabs(sites[l][i].biome);
}
SDL_Rect drect = {i * globals::SPRITE_SIZE * globals::SPRITE_SCALE, l * globals::SPRITE_SIZE * globals::SPRITE_SCALE,
globals::SPRITE_SIZE * globals::SPRITE_SCALE, globals::SPRITE_SIZE * globals::SPRITE_SCALE};
graphics->blitOnRenderer(_biomeTexture, &srect, &drect);
}
}
}
因此,在这个语境中,每个瓦片被称为“站点”,这是因为它们还存储诸如湿度、温度等信息。
在生成过程中,为每个站点分配了一个生物群系,每个生物群系基本上都是一个ID,每个陆地生物群系的ID都大于0,而每个水生ID都为0或更低。
这使得我可以将每个生物群系精灵按ID排序放入“biome_sprites.png”图像中。所有陆地精灵基本上都在第一行,而所有水域瓦片都在第二行。这样,我就不必手动为生物群系分配精灵,该方法可以通过将瓷砖大小(基本上是宽度)与生物群系相乘来自行完成。
这是我的SDD/GDD中的生物群系ID表和实际的精灵表。
{kind=link}
{kind=link}
graphics类中的blitOnRenderer方法基本上只是运行一个SDL_RenderCopy将纹理复制到渲染器上。
void Graphics::blitOnRenderer(SDL_Texture *texture, SDL_Rect
*sourceRectangle, SDL_Rect *destinationRectangle) {
SDL_RenderCopy(this->_renderer, texture, sourceRectangle, destinationRectangle);
}
在游戏循环中,每帧都会调用RenderClear和RenderPresent函数。
我真心希望我已经讲清楚了,如果有任何问题,请随时问,我是寻求帮助的人,所以我会尽力配合 :D
SDL_Texture而不是SDL_Surface。 - BlazeblitOnRenderer代码。没有它会很难帮助您。根据当前状态,我可以建议使用每个单元格由四边形表示的网格,并具有drect位置和srect纹理坐标。或者您可以尝试将所有相同类型的图块批处理到一个调用中。 - Michael Nastenko