如何实现JavaScript函数来计算给定句子中每个单词的频率。
这是我的代码:
function search () {
var data = document.getElementById('txt').value;
var temp = data;
var words = new Array();
words = temp.split(" ");
var uniqueWords = new Array();
var count = new Array();
for (var i = 0; i < words.length; i++) {
//var count=0;
var f = 0;
for (j = 0; j < uniqueWords.length; j++) {
if (words[i] == uniqueWords[j]) {
count[j] = count[j] + 1;
//uniqueWords[j]=words[i];
f = 1;
}
}
if (f == 0) {
count[i] = 1;
uniqueWords[i] = words[i];
}
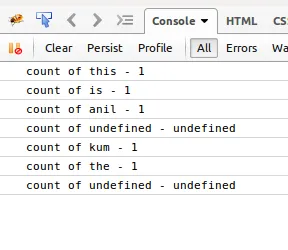
console.log("count of " + uniqueWords[i] + " - " + count[i]);
}
}
我无法跟踪问题...非常感谢任何帮助。
is的计数 - 1
the的计数 - 2...
输入: 这是安尼尔是库姆安尼尔
var words = [],而不是var words = new Array()。 - royhowiefunction wordCounts(n){return n.match(/\w+/g).reduce(function(n,r){return n.hasOwnProperty(r)?++n[r]:n[r]=1,n},{})}- ashleedawg