我阅读了Mark Harris的《在CUDA中优化并行归约》一文,发现它非常有用。但有时我仍然无法理解其中的1或2个概念。在第18页上写道:
//First add during load
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
优化代码:在两个负载和第一个减少的加法中:
// perform first level of reduction,
// reading from global memory, writing to shared memory
unsigned int tid = threadIdx.x; ...1
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x; ...2
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x]; ...3
__syncthreads(); ...4
我无法理解第二行;如果我有256个元素,而我选择128作为块大小,那么为什么要乘以2?请说明如何确定块大小?
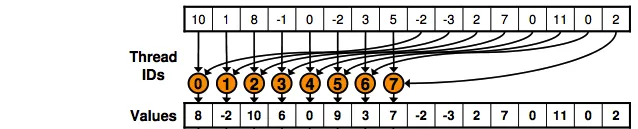
g_idata中元素的总数为256,在第二个段落中为512。正确:在优化的代码中,sdata要小2倍(你只有128个元素,或者在第二个段落中是2 * 128),但这已足够用于减少的目的。 - P Marecki