我知道交叉验证用于选择好的参数。在找到它们之后,我需要重新训练整个数据但不使用-v选项。
但我面临的问题是,在使用-v选项进行训练后,我得到了交叉验证准确率(例如85%),但没有模型,也无法看到C和gamma的值。在这种情况下,我该如何重新训练?
顺便说一句,我正在应用10折交叉验证。
optimization finished, #iter = 138
nu = 0.612233
obj = -90.291046, rho = -0.367013
nSV = 165, nBSV = 128
Total nSV = 165
Cross Validation Accuracy = 98.1273%
需要帮助...
为了得到最好的C和gamma值,我使用了LIBSVM FAQ中提供的代码。
bestcv = 0;
for log2c = -6:10,
for log2g = -6:3,
cmd = ['-v 5 -c ', num2str(2^log2c), ' -g ', num2str(2^log2g)];
cv = svmtrain(TrainLabel,TrainVec, cmd);
if (cv >= bestcv),
bestcv = cv; bestc = 2^log2c; bestg = 2^log2g;
end
fprintf('(best c=%g, g=%g, rate=%g)\n',bestc, bestg, bestcv);
end
end
另一个问题:使用-v选项后的交叉验证准确性是否类似于我们在没有使用-v选项进行训练并使用该模型进行预测时得到的准确性?这两个准确性是否相似?
另一个问题:交叉验证基本上通过避免过拟合来提高模型的准确性。因此,在它可以改进之前,需要先有一个模型。我对吗?此外,如果我有一个不同的模型,那么交叉验证的准确性就会不同。我对吗?
还有一个问题:在交叉验证准确性中,C和gamma的值是多少?
图表如下
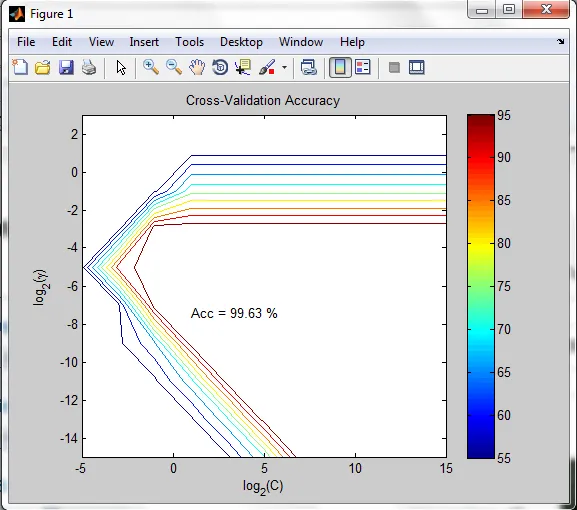
然后C的值为2,gamma=0.0078125。但是当我用新参数重新训练模型时,这个值与99.63%不同。可能有什么原因吗? 提前感谢...
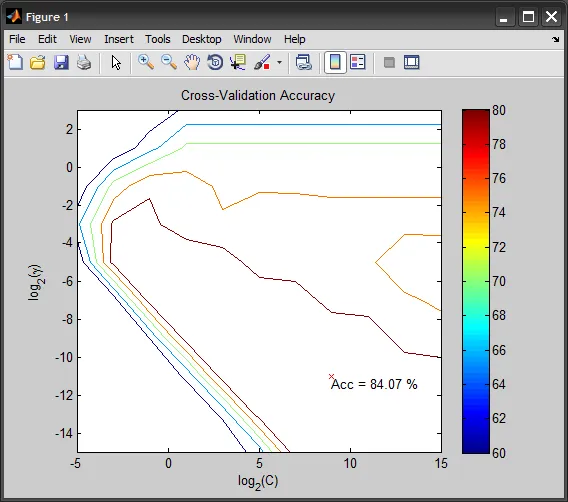
C=2^9和gamma=2^-11)。 - AmroC(idx)和gamma(idx)。 - Amro