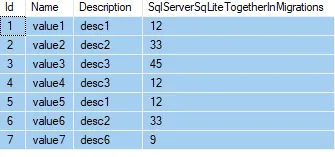
表名为“OrderDetails”,下面是列名:
如何选择多列并按ProductID列分组,因为ProductName不唯一?
在此过程中,还要获取OrderQuantity列的总和。
OrderDetailID || ProductID || ProductName || OrderQuantity
我试图选择多列并按ProductID分组,同时对OrderQuantity求和。
Select ProductID,ProductName,OrderQuantity Sum(OrderQuantity)
from OrderDetails Group By ProductID
当然,这段代码会报错。我需要添加其他列名进行分组,但那不是我想要的方式,而且由于我的数据有很多项,因此以那种方式结果是出乎意料的。
示例数据查询:
从OrderDetails中选择ProductID、ProductName、OrderQuantity
以下为结果:
ProductID ProductName OrderQuantity
1001 abc 5
1002 abc 23 (ProductNames can be same)
2002 xyz 8
3004 ytp 15
4001 aze 19
1001 abc 7 (2nd row of same ProductID)
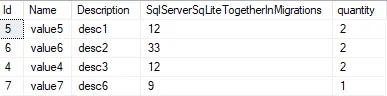
期望结果:
ProductID ProductName OrderQuantity
1001 abc 12 (group by productID while summing)
1002 abc 23
2002 xyz 8
3004 ytp 15
4001 aze 19
如何选择多列并按ProductID列分组,因为ProductName不唯一?
在此过程中,还要获取OrderQuantity列的总和。