我有一个方法如下所示(请忽略代码优化问题)。这个方法替换Unicode字符(孟加拉字符)
static String swap(String temp, char c)
{
Integer length=temp.length();
char[] charArray = temp.toCharArray();
for(int u=0;u<length;u++)
{
if(charArray[u]==c)
{
char g=charArray[u];
charArray[u]=charArray[u-1];
charArray[u-1]=g;
}
}
String string2 = new String(charArray);
return string2;
}
在调试过程中,我得到了charArray的值,如下图所示:
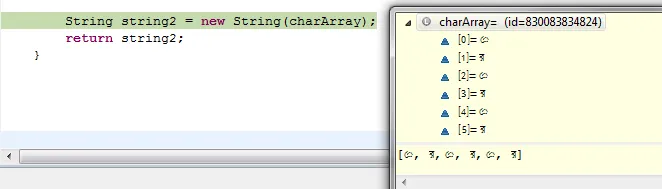
请注意,字符以我想要的顺序排列。
但是,在执行语句后,存储在字符串变量中的值不匹配。如下所示:
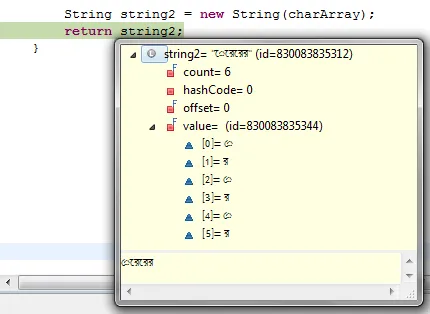
我想将字符串显示为“রেরেরে”,但它显示为“েরেরের”,这不是我想要的。请告诉我我做错了什么。
\u09B0\u09C7\u09B0\u09C7\u09B0\u09C7? 如果你需要解决这个特定需求,我可以尝试提供一个解决方案。但是如果你想要理解它的工作原理,那你需要了解3个孟加拉字符在Java中如何映射到6个字符,并且为什么替换1个Java字符是不好的想法。 - Vineet Reynoldsরেরেরে和েরেরের并查看Unicode代码点表示。通过将\u09B0\u09C7替换为\u09C7\u09B0,您确实没有实现任何有用的东西。 - Vineet Reynolds