这不是一个完整的解决方案,但它可能会带来更好的结果。
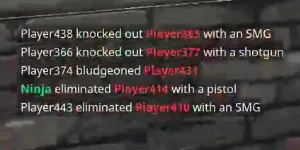
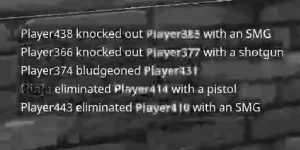
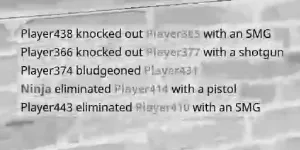
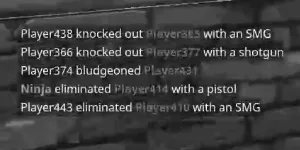
通过将您的数据从BGR(或RGB)转换为CIE-Lab,您可以将灰度图像处理为颜色通道a*和b*的加权和。
这个灰度图像将增强文本的颜色区域。
但是通过调整阈值,您可以从这个灰度图像中分割出原始图像中的彩色单词,并从a L通道阈值中获取其他单词。
位与运算符应该足以合并两个分割图像。
如果您可以拥有对比度更好的图像,最后一步可以是基于轮廓的填充。
为此,请查看函数“cv2.findContours”的RETR_FLOODFILL。
任何其他包中的孔填充函数也可能适用于此目的。
这里是一个展示我想法的第一部分的代码。
import cv2
import numpy as np
from matplotlib import pyplot as plt
I = cv2.UMat(cv2.imread('/home/smile/QSKN.png',cv2.IMREAD_ANYCOLOR))
Lab = cv2.cvtColor(I,cv2.COLOR_BGR2Lab)
L,a,b = cv2.split(Lab)
Ig = cv2.addWeighted(cv2.UMat(a),0.5,cv2.UMat(b),0.5,0,dtype=cv2.CV_32F)
Ig = cv2.normalize(Ig,None,0.,255.,cv2.NORM_MINMAX,cv2.CV_8U)
_, Ib = cv2.threshold(Ig,0.,255.,cv2.THRESH_OTSU)
_, Lb = cv2.threshold(cv2.UMat(L),0.,255.,cv2.THRESH_OTSU)
_, ax = plt.subplots(2,2)
ax[0,0].imshow(Ig.get(),cmap='gray')
ax[0,1].imshow(L,cmap='gray')
ax[1,0].imshow(Ib.get(),cmap='gray')
ax[1,1].imshow(Lb.get(),cmap='gray')