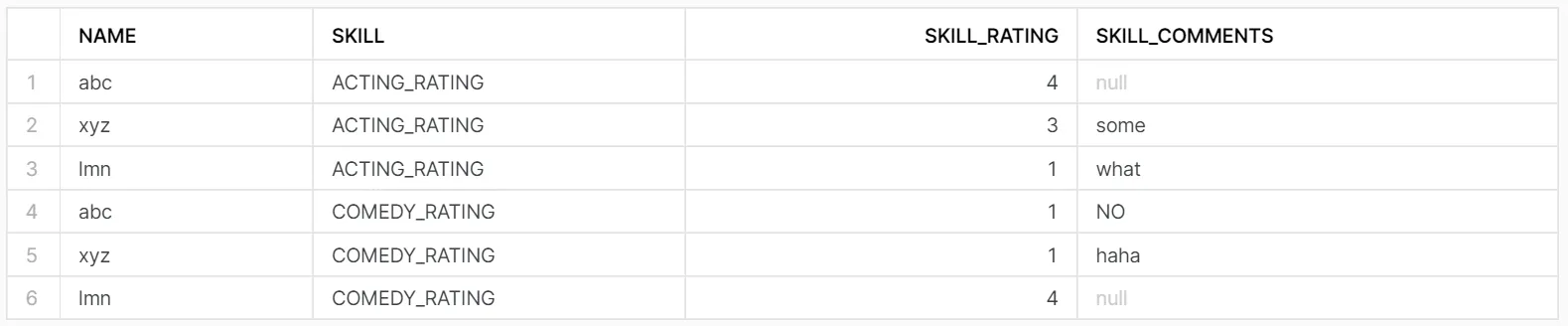
我有一个如下所示的表格:
 我需要按照以下方式将评分和评论展开(unpivot):
我需要按照以下方式将评分和评论展开(unpivot):
 在 Snowflake 中,最好的方法是什么?
在 Snowflake 中,最好的方法是什么?
注意:评论列中有一些单元格为
添加详细信息:
我需要按照以下方式将评分和评论展开(unpivot):
在 Snowflake 中,最好的方法是什么?注意:评论列中有一些单元格为
NULL。添加详细信息:
create or replace table reviews(name varchar(50), acting_rating int, acting_comments text, comedy_rating int, comedy_comments text);
insert into reviews values
('abc', 4, NULL, 1, 'NO'),
('xyz', 3, 'some', 1, 'haha'),
('lmn', 1, 'what', 4, NULL);
select * from reviews;
select name, skill, skill_rating, comments
from reviews
unpivot(skill_rating for skill in (acting_rating, comedy_rating))
unpivot(comments for skill_comments in (acting_comments,comedy_comments))
--Following where clause is added to filter the irrelevant comments due to multiple unpivots
where substr(skill,1,position('_',skill)-1) = substr(skill_comments,1,position('_',skill_comments)-1)
order by name;
将会产生所期望的结果,但如果数据中有 NULL 值,则未旋转的行将在输出中丢失:
NAME SKILL SKILL_RATING COMMENTS
abc COMEDY_RATING 1 NO
lmn ACTING_RATING 1 what
xyz ACTING_RATING 3 some
xyz COMEDY_RATING 1 haha

{kind=link}
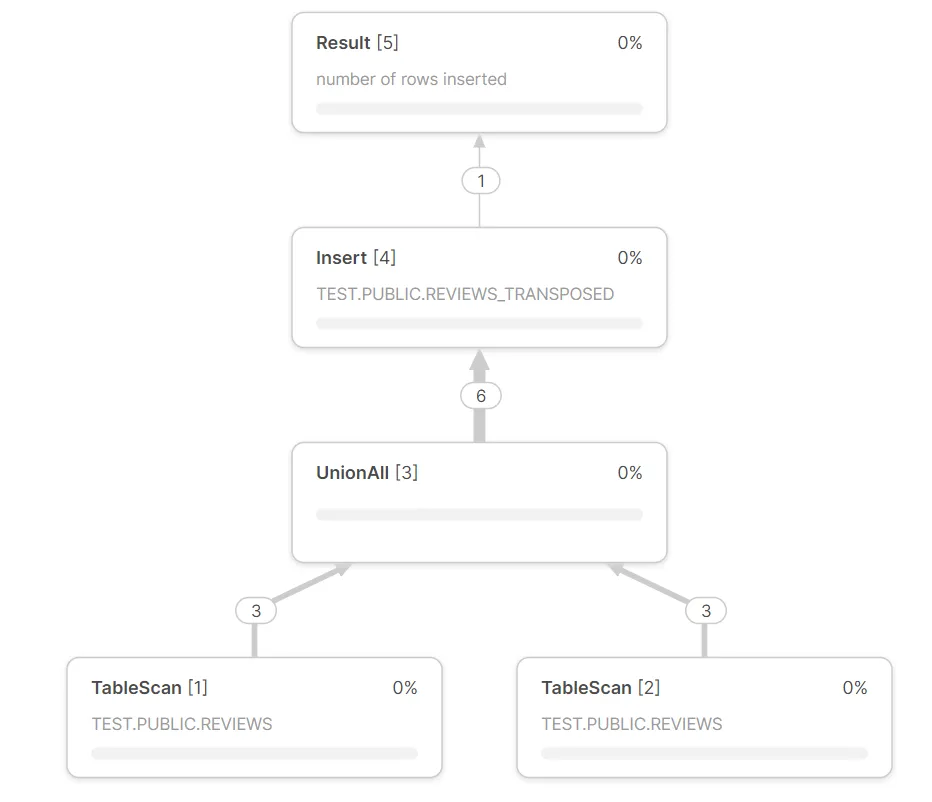
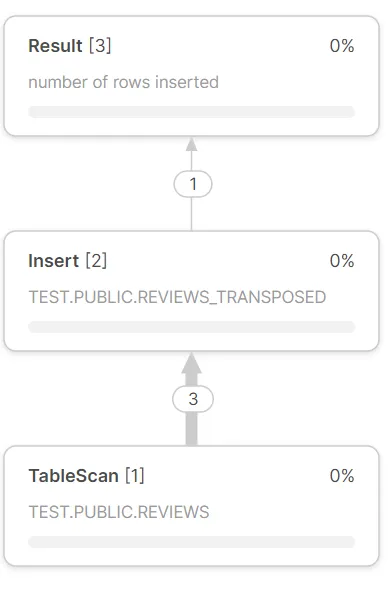
INSERT ALL,当结果应该保存在表中时。 - Lukasz Szozda