我正在使用正则表达式将字符串 <书名> by <作者名> 拆分成书名和作者姓名。
re.split(r'\bby\b', text, 0, re.I)
但是当书名中包含“by”这个词时会出现问题(例如Death by Blackhole by Tyson =>['Death', 'by Black...'])
我该如何通过搜索模式的最后一个出现位置来拆分字符串?
我有一个直觉——正/负面向前/向后看可能在这里有用,但目前正在努力构建正确的语法。
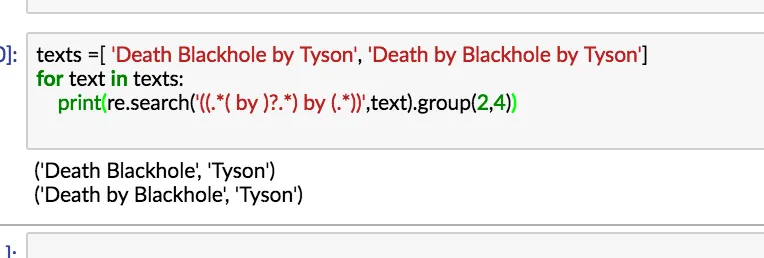
你可以从分割中重构:
```parts = re.split(r'\bby\b', text, 0, re.I)
book, author = 'by'.join(parts[:-1]), parts[-1]
或者进行完全匹配:
match = re.match(r'(.*)\bby\b(.*)', text, re.I)
by(?!.*by.*)
re.split(r'\bby\b(?!.*\bby\b)', text, 0, re.I)。 - Wiktor Stribiżew^(.+)\bby\b(.+)$可以同时匹配作者和标题(+是贪婪的,所以会取最后一个出现的)。 - ssc-hrep3