我有一个数据集,其中每年都有一些基于特定年份的列数据。
我想要逐对计算数据的平均值,从数据框的底部开始。最后一行必须与原始数据集相同。例如,对于第一行,我们将得到类似以下的结果:
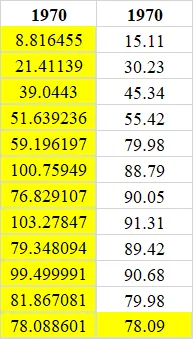
result_birth <- tibble::tibble( "1970" =c(8.816455, 21.41139,39.0443,51.639236, 59.196197, 100.759485, 76.829107,103.278472,79.348094,99.499991, 81.867081, 78.088601),
"1971"= c(18.878066 ,30.204906 ,42.790284 ,65.443964 ,69.219577 ,80.546417 ,114.526936 ,94.390332 ,108.234248 ,83.063492 ,103.200096 ,72.99519 ),
"1972"= c(8.801375 ,22.632107 ,36.462839 ,56.580268 ,69.153661 ,76.697696 ,80.469714 ,109.388518 ,96.815125 ,108.131179 ,69.153661 ,91.785768 ),
"1973"= c(14.675905 ,20.790865 ,31.797794 ,64.818581 ,58.70362 ,86.832438 ,85.609446 ,96.616375 ,97.839367 ,78.271493 ,105.177319 ,53.811652 ))
我想要逐对计算数据的平均值,从数据框的底部开始。最后一行必须与原始数据集相同。例如,对于第一行,我们将得到类似以下的结果:
nrows <- nrow(result_birth)
total_birth <- data.frame(matrix(NA, nrow = nrows, ncol =
ncol(result_birth)))
for (i in 1:ncol(result_birth)) {
for (j in 2:nrows) {
total_birth[j, i]<-(result_birth[j,i]+result_birth[j-1,i])/2
}
}