我已经在一组4个Kepler K20c GPU上进行了并发执行的实验。我考虑了8个测试用例,其中相应的代码及分析器时间线如下所示。
测试用例#1 - “广度优先”方法 - 同步复制
- 代码 -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices = (double *)malloc(N * sizeof(double));
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- 分析器时间轴 -

从图中可以看出,使用cudaMemcpy无法实现复制并发,但是在内核执行中实现了并发。
测试用例#2 - "深度优先"方法 - 同步复制
- 代码 -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices = (double *)malloc(N * sizeof(double));
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpy(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- 代码 -
- 分析器时间线 -

这一次,并发不是在内存复制或内核执行中实现的。
测试用例#3-"深度优先"方法-使用流进行异步复制
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
T *h_data;
cudaStream_t stream;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
gpuErrchk(cudaStreamCreate(&plan.stream));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice, plan[k].stream));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE, 0, plan[k].stream>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost, plan[k].stream));
}
gpuErrchk(cudaDeviceReset());
}
- 性能分析时间轴 -

如预期一样,实现了并发。
测试用例#4 - “深度优先”方法 - 在默认流中进行异步复制
- 代码 -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
T *h_data;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- 分析器时间轴 -

尽管使用默认流,但仍然实现了并发。
测试用例#5 - “深度优先”方法 - 在默认流中异步复制和独特主机cudaMallocHost向量
- 代码 -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices; gpuErrchk(cudaMallocHost(&inputMatrices, N * sizeof(double)));
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- 分析器时间线 -

并发性再次实现。
测试用例#6 - 带有流异步复制的“广度优先”方法
- 代码 -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
T *h_data;
cudaStream_t stream;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
gpuErrchk(cudaStreamCreate(&plan.stream));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice, plan[k].stream));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE, 0, plan[k].stream>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost, plan[k].stream));
}
gpuErrchk(cudaDeviceReset());
}
- 分析器时间轴 -

并发性实现,与相应的“深度优先”方法相同。
测试用例#7 - “广度优先”方法 - 在默认流中进行异步复制
- 代码 -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
T *h_data;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- 分析器时间轴 -
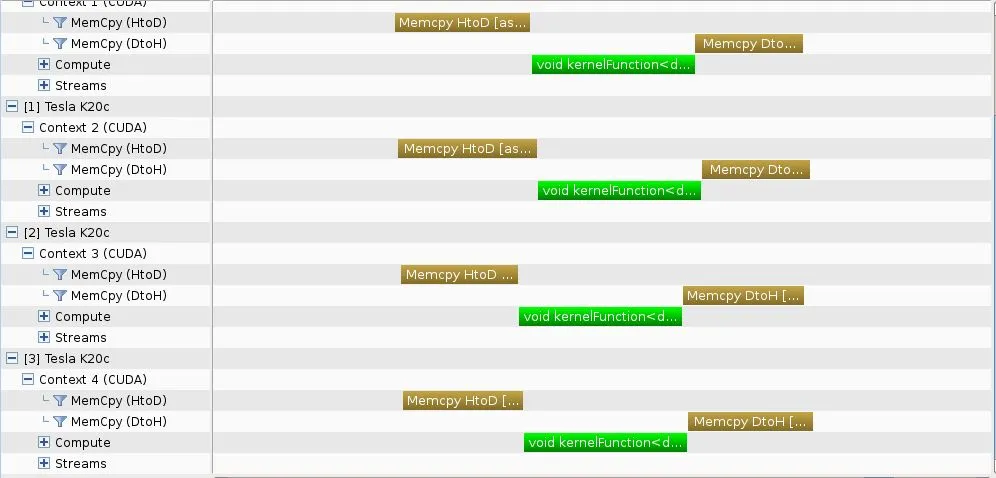
并发性可在相应的“深度优先”方法中实现。
测试用例#8 -“广度优先”方法 - 默认流内异步复制和唯一主机cudaMallocHost矢量
- 代码 -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
template<class T>
struct plan {
T *d_data;
};
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices; gpuErrchk(cudaMallocHost(&inputMatrices, N * sizeof(double)));
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- 分析器时间轴 -

并发性的实现方式与相应的“深度优先”方法相同。
结论
使用异步复制可以保证并发执行,无论是使用专门创建的流还是使用默认流。
注意事项
在上述所有示例中,我都特别注意为GPU提供足够的工作量,包括复制和计算任务。如果未能为集群提供足够的工作量,则可能无法观察到并发执行。
cudaMemcpyAsync的流,否则行为与cudaMemcpy相同。为了使该代码工作,先执行 所有 内核启动,然后再执行所有复制操作。复制仍将相互阻塞,但所有内核将并行运行。 - talonmies