我是机器学习和Tensorflow的新手。我按照Tensorflow网站上的教程训练了一个用于回归的神经网络。我有3个输入列和2个输出列,我将其标记为“标签”。当使用测试数据时,该网络似乎可以很好地预测数据,但是当我尝试预测测试集和训练集之外的数据时,通过导入仅具有3个输入列的文件,它会给出错误,显示“期望dense_input的形状为(5,),但得到形状为(3,)的数组”。我知道这是因为模型是在一个由5列数据组成的数据集上进行训练的,但我想要从模型中预测未知值(一旦训练完成),并且不知道输出结果。当我只知道输入(3列)时,如何预测结果?如果我必须知道输出结果(我确定我不必知道),那么进行这种回归分析的意义是什么?
我的数据看起来像这样: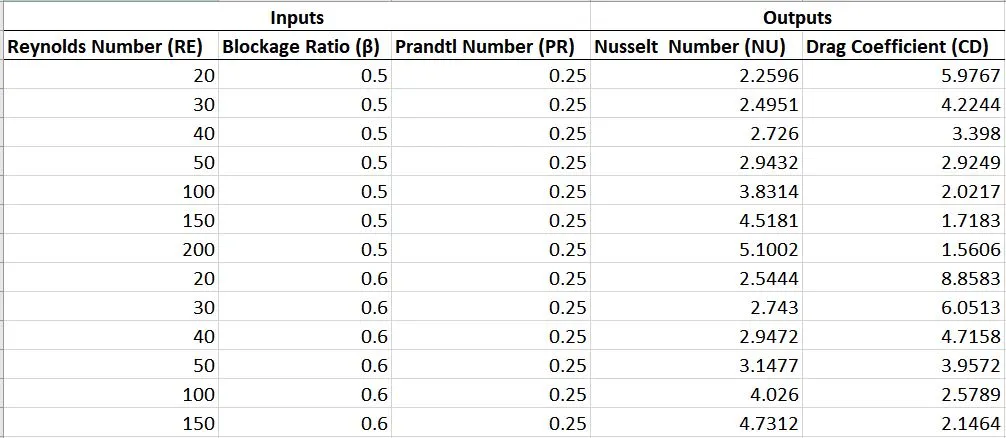
我的数据看起来像这样:
我正在尝试让神经网络以这种方式运行: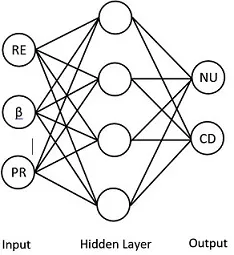
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import pickle
column_names = ['Reynolds Number', 'Blockage Ratio', 'Prandtl Number', 'Nusselt Number', 'Drag Coefficient']
dataset = pd.read_csv('WW.csv', names=column_names, skipinitialspace=True)
train_dataset = dataset.sample(frac=0.9,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
train_labels = train_dataset.iloc[:, 3:].values
test_labels = test_dataset.iloc[:, 3:].values
print(train_dataset)
print(test_dataset)
def build_model():
model = keras.Sequential([
keras.layers.Dense(3, activation='relu', input_shape=[len(train_dataset.keys())]),
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(2)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
model.summary()
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 5000
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=500)
history = model.fit(train_dataset, train_labels, epochs=EPOCHS, validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
model.save("model.h5")
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
print('\n', hist.tail())
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'],
label = 'Val Error')
plt.ylim([0,5])
plt.legend()
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'],
label = 'Val Error')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history)
test_predictions = model.predict(test_dataset)
test_dataset['Predicted Nu'], test_dataset['Predicted CD'] = test_predictions[:,0], test_predictions[:,1]
print(test_dataset)
np.savetxt('test_dataset.txt', test_dataset, delimiter=',')
predict = model.predict(train_dataset)
train_dataset['Predicted Nu'], train_dataset['Predicted CD'] = predict[:,0], predict[:,1]
print(train_dataset)
np.savetxt('train_dataset.txt', train_dataset, delimiter=',')
class_names = ['Reynolds Number', 'Blockage Ratio', 'Prandtl Number', 'junk Nusselt Number', 'junk Drag Coefficient']
all_inputs = pd.read_csv('Predict_Input.csv', names=class_names, skipinitialspace=True)
all_outputs = model.predict(all_inputs)
all_inputs['Predicted Nu'], all_inputs['Predicted CD'] = all_outputs[:,0], all_outputs[:,1]
print(all_inputs)
(batch_size, 5)的输入,而你正在尝试预测一个(batch_size, 2)的输出,这已经包含在训练数据中了?如果我错了,请纠正我,因为这样做没有太多意义,你正在预测你已经知道的东西。也许你可以用一个例子或图表来解释一下你需要什么? - thushv89