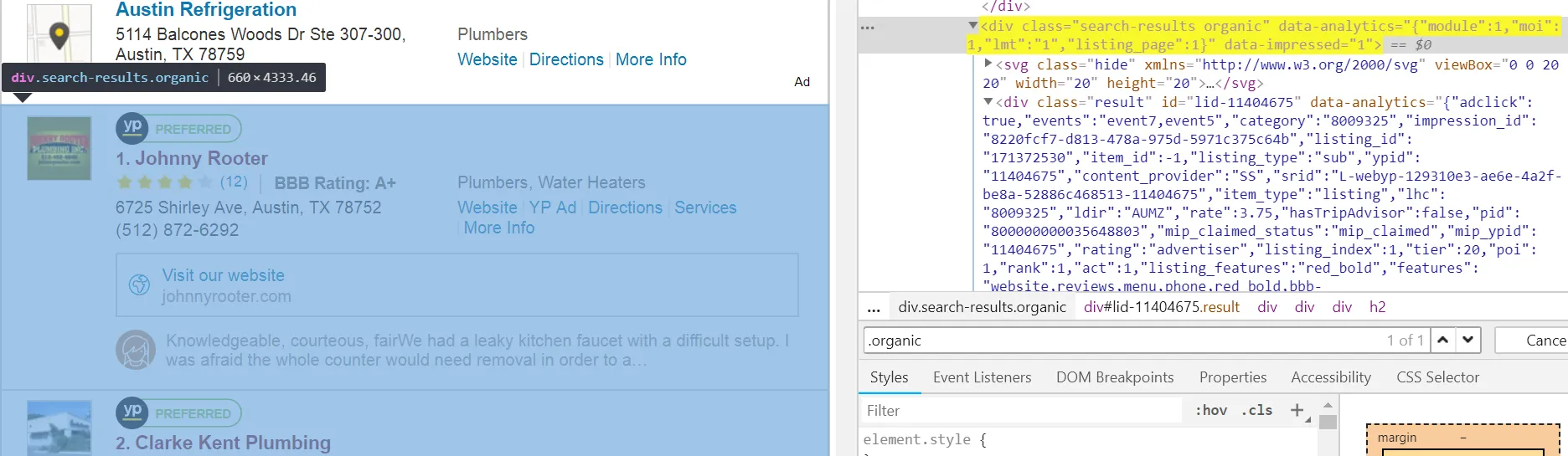
我想从黄页获取数据,但我只需要数字管道工。但我无法在h2 class='n'中获取文本数字。我可以获取class="business-name"的文本,但我只需要数字管道工而不包括广告。我错在哪里?非常感谢。
这是html代码:
<div class="info">
<h2 class="n">1. <a class="business-name" href="/austin-tx/mip/johnny-rooter-11404675?lid=171372530" rel="" data-impressed="1"><span>Johnny Rooter</span></a></h2>
</div>
这是我的Python代码:
import requests
from bs4 import BeautifulSoup as bs
url = "https://www.yellowpages.com/austin-tx/plumbers"
req = requests.get(url)
data = req.content
soup = bs(data, "lxml")
links = soup.findAll("div", {"class": "info"})
for link in links:
for content in link.contents:
try:
print(content.find("h2", {"class": "n"}).text)
except:
pass