亲爱的Stackoverflow社区,
我正在尝试理解DRAM访问性能极限的计算,但我的基准测试结果与规格书中的数字相差甚远。当然,人们不会期望达到理论极限,但可能有一些解释为什么相差如此之远。
例如,我在我的系统上测量DRAM访问速度约为11 GB/s,但WikiChip或 JEDEC规格列出双通道DDR4-2400系统的峰值性能为38.4 GB/s。
我的测量是否有误或这些数字只是计算峰值内存性能的错误数字?
测量方法
在我的系统上,使用一颗1.8GHz的英特尔酷睿i7-8550U处理器,该处理器基于卡比湖微架构。

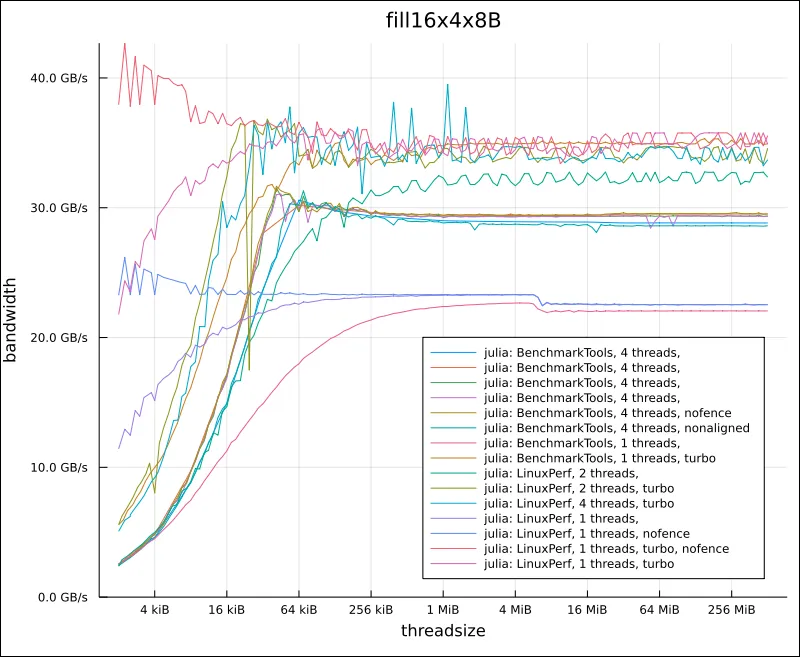
事实是,lshw 显示了两个 memory 条目。
*-memory
...
*-bank:0
...
slot: ChannelA-DIMM0
width: 64 bits
clock: 2400MHz (0.4ns)
*-bank:1
...
slot: ChannelB-DIMM0
width: 64 bits
clock: 2400MHz (0.4ns)
那么这两个应该以“双通道”模式运行(这自动进行吗?)。
我设置了系统以减少测量噪声:
- 禁用频率缩放
- 禁用地址空间布局随机化
- 将
scaling_governor设置为performance - 使用
cpuset将基准测试隔离在自己的核心上 - 设置一个niceness值为-20
- 使用最少量的进程运行无头系统
然后,我从pmbw - Parallel Memory Bandwidth Benchmark / Measurement程序的ScanWrite256PtrUnrollLoop基准测试开始:
pmbw -f ScanWrite256PtrUnrollLoop -p 1 -P 1
可以使用内部循环进行检查
gdb -batch -ex "disassemble/rs ScanWrite256PtrUnrollLoop" `which pmbw` | c++filt
看起来这个基准测试创建了一个“流”,使用vmovdqa移动对齐的打包整数值AVX256指令来饱和CPU的内存子系统
<+44>:
vmovdqa %ymm0,(%rax)
vmovdqa %ymm0,0x20(%rax)
vmovdqa %ymm0,0x40(%rax)
vmovdqa %ymm0,0x60(%rax)
vmovdqa %ymm0,0x80(%rax)
vmovdqa %ymm0,0xa0(%rax)
vmovdqa %ymm0,0xc0(%rax)
vmovdqa %ymm0,0xe0(%rax)
vmovdqa %ymm0,0x100(%rax)
vmovdqa %ymm0,0x120(%rax)
vmovdqa %ymm0,0x140(%rax)
vmovdqa %ymm0,0x160(%rax)
vmovdqa %ymm0,0x180(%rax)
vmovdqa %ymm0,0x1a0(%rax)
vmovdqa %ymm0,0x1c0(%rax)
vmovdqa %ymm0,0x1e0(%rax)
add $0x200,%rax
cmp %rsi,%rax
jb 0x37dc <ScanWrite256PtrUnrollLoop(char*, unsigned long, unsigned long)+44>
作为 Julia 中类似的基准,我想到了以下内容:
const C = NTuple{K,VecElement{Float64}} where K
@inline function Base.fill!(dst::Vector{C{K}},x::C{K},::Val{NT} = Val(8)) where {NT,K}
NB = div(length(dst),NT)
k = 0
@inbounds for i in Base.OneTo(NB)
@simd for j in Base.OneTo(NT)
dst[k += 1] = x
end
end
end
当调查这个fill!函数的内部循环时
code_native(fill!,(Vector{C{4}},C{4},Val{16}),debuginfo=:none)
我们可以看到,这也创建了类似的“流”
vmovups 移动非对齐打包单精度浮点值指令:L32:
vmovups %ymm0, -480(%rcx)
vmovups %ymm0, -448(%rcx)
vmovups %ymm0, -416(%rcx)
vmovups %ymm0, -384(%rcx)
vmovups %ymm0, -352(%rcx)
vmovups %ymm0, -320(%rcx)
vmovups %ymm0, -288(%rcx)
vmovups %ymm0, -256(%rcx)
vmovups %ymm0, -224(%rcx)
vmovups %ymm0, -192(%rcx)
vmovups %ymm0, -160(%rcx)
vmovups %ymm0, -128(%rcx)
vmovups %ymm0, -96(%rcx)
vmovups %ymm0, -64(%rcx)
vmovups %ymm0, -32(%rcx)
vmovups %ymm0, (%rcx)
leaq 1(%rdx), %rsi
addq $512, %rcx
cmpq %rax, %rdx
movq %rsi, %rdx
jne L32
现在,所有这些基准测试都以某种方式显示了三个缓存和主内存的不同“性能平台”。
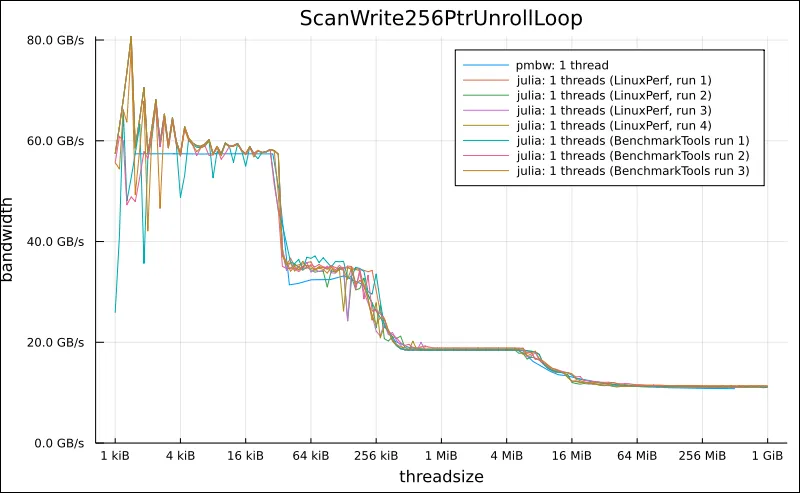
有趣的是,对于更大的测试大小,它们都绑定在约11 GB/s左右: