您将获得n对数字。在每一对中,第一个数字总是小于第二个数字。当且仅当b小于c时,对(c,d)可以跟随(a,b)。可以以这种方式形成一系列对。找到形成的最长配对链。我在Amazon的面试中遇到了这个问题,但无法找出答案,只知道它与LIS问题有关。
5个回答
14
由于每个(X,Y)对的两个值必须按顺序排列(X < Y),并且一个对的Y值必须小于下一个对的X值,因此您实际上正在沿着一个维度构建一个连续的值链。 您只需按Y值排序即可。
给定这个示例数据:
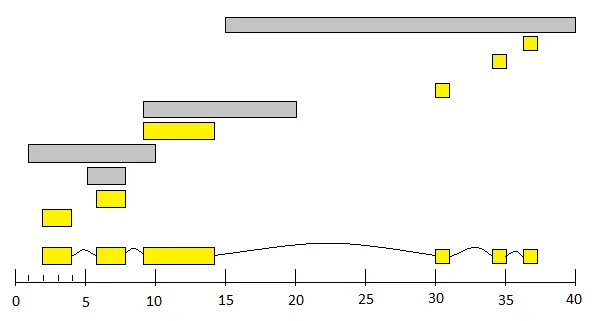
(15,40) (5,8) (1,10) (6,8) (9,20) (2,4) (36,37) (34,35) (9,14) (30,31)
按Y排序以获得:
(2,4) (6,8) (5,8) (1,10) (9,14) (9,20) (30,31) (34,35) (36,37) (15,40)
然后循环遍历,如果其X大于链中最后一个Y,则将一对加入链中,否则忽略它。
请注意,在这个例子中,(6,8) 恰好在 (5,8) 之前排序。当它们的 Y 值相等时,选择哪一对用于链并不重要,只要 X 值满足比之前的 Y 值大的条件即可。
这里是一个显示排序后成对数据的图表,它们以条形图形式出现在数字线上。从第一对 (2,4) 开始,每一个添加到底部的链中的对都会被着成黄色。视觉上,灰色的对被跳过是因为底部的链中已有一个黄色的对“挡住”了它被放入链中(存在值重叠)。
证明: 唯一能够将更多对加入到链中的方法是,用一个 Y 值较小的对来替换一个对,以便下一个对可以具有较小的 X 值,从而可能适合在之前无法适应的位置放置另一对。如果您使用具有相同 Y 值的对进行替换,则不会获得任何好处。如果替换具有较大的 Y 值,则所有您所做的就是可能阻止一些之前适合的对。
由于成对数据已按 Y 值排序,因此您永远不会找到比更小的 Y 值更小的替代品。向“前”查看排序后的对,它们都将具有相同或更大的 Y 值。向“后”查看时,最初从链中消除的任何对都是因为 X 值不够高,这仍然是情况。
- Brian Stephens
2
你能证明这将是可能的最长链吗?谢谢! - sww
你刚刚发现了活动选择问题的解决方案!!非常棒的答案!! - sww
2
首先,这个问题可以被看作是在一个二维网格上绘制点,每个点的x坐标小于该点的y坐标。现在你需要找到最长的链,使得每个i+1 th点都在第i个点的右上方(并且第i个点的y坐标小于i+1th点的x坐标)。
现在让我们首先根据它们的x坐标对点进行排序。然后我们从最低的x坐标开始访问已排序的点,如果x坐标有相同的,则我们将首先访问y坐标较高的点。例如,如果我们正在处理第i个点,我们知道所有已经访问过的点的x坐标都比第i个点低或相似。因此,在点i结束的最长链将是我们已经获得的y坐标<=当前点的x坐标的最长链。
我们可以使用高效的数据结构(如段树或二进制索引树)高效地完成这项工作。
这个解决方案的运行时间是:O(NlgN),其中N是点的数量(给定问题中的对数)。
现在让我们首先根据它们的x坐标对点进行排序。然后我们从最低的x坐标开始访问已排序的点,如果x坐标有相同的,则我们将首先访问y坐标较高的点。例如,如果我们正在处理第i个点,我们知道所有已经访问过的点的x坐标都比第i个点低或相似。因此,在点i结束的最长链将是我们已经获得的y坐标<=当前点的x坐标的最长链。
我们可以使用高效的数据结构(如段树或二进制索引树)高效地完成这项工作。
这个解决方案的运行时间是:O(NlgN),其中N是点的数量(给定问题中的对数)。
- Fallen
1
2然而,请注意条件并不是完全指向上方和右方。考虑点(3,10)和(4,11)。第二个点向上和向右,但这不是可接受的链条,因为b = 10不小于c = 4。尽管如此,我认为如果你仅将其更改为搜索当前点y坐标< x坐标的最长链,那么此算法可以工作。 - Peter de Rivaz
1
创建一棵树是解决这个问题的基本方法,其中每个节点都是一对,并在一个节点到另一个节点时构建有向边,当它是合法的时候(即,“如果且仅如果b小于c,则一对(c,d)可以跟随(a,b)”)。您可以从每个节点进行修改后的广度优先遍历,以跟踪从该节点开始的最长路径的长度,完成后只需查看所有节点以找到最长路径。
- Eric Kim
1
我们可以采用Brian的方法,基于y值对所有配对进行排序。这将确保先前配对的X <下一个配对的y的所需条件。
现在,我们只需要在新的配对列表中找到x的最长递增子序列即可。我们可以通过对所有x进行排序,并在排序后的x和之前创建的新列表之间找到最长公共子序列来实现这一点。
- Anjali Singhal
0
我认为最长链的一个特征是它最小化了任何相邻元组的总跨度(以最大化任何范围内可能的元组数量)。
在这种情况下,正如Brian Stephens所建议的那样,我们只需要按第二个数字升序排序(以保证在搜索下一个元组时具有最小跨度),并从排序列表中的第一个元组开始构建链。
我们可以通过假设S(0)是从第一个元组开始的链来证明这个解决方案是最优的,存在一个S(i),其中i不在S(0)中,比S(0)更长;因此也存在一个比S(1)更长的链S(i+1)。我们知道i的开始必须在i-1的结束之前,否则它将被包含在S(0)中。现在,如果i-1的结束等于i的结束,S(i+1)将成为S(0)的一部分,这与我们的前提相矛盾。或者,如果i的结束大于i-1的结束,再次S(i+1)将被包含在S(0)中。由于列表按此属性排序,因此i的结束不能小于i-1的结束。
- גלעד ברקן
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接