我一直在尝试使用随机写入工作负载,在NVMe SSD上使用多个线程向一个或多个文件的不同偏移量进行写入。我正在使用Linux机器,写入是同步进行的,并且使用直接I/O进行(即,文件使用
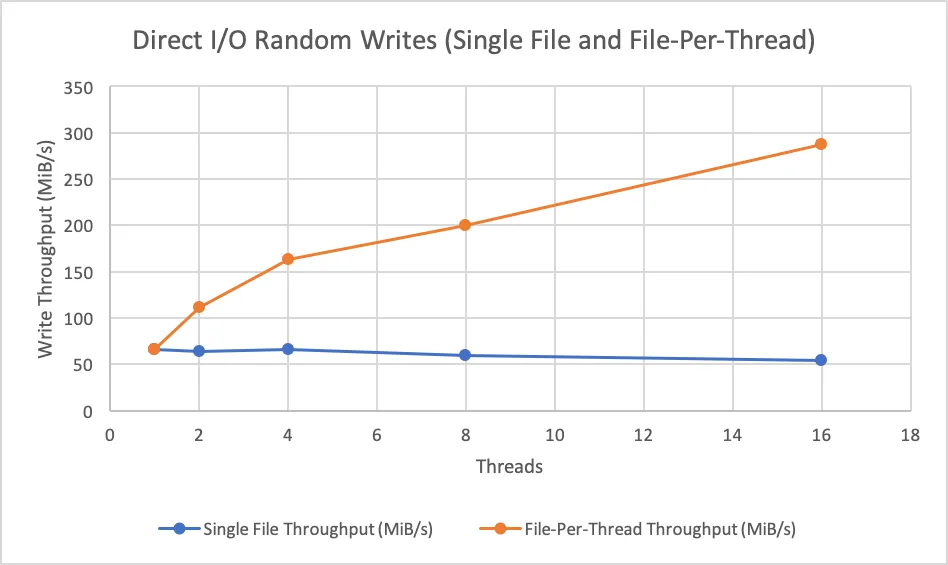
我注意到,如果线程同时写入单个文件,则当线程数增加时,实现的写入吞吐量不会增加(即,写入似乎是串行应用而非并行应用)。但是,如果每个线程都写入自己的文件,则可以获得吞吐量增加(高达SSD制造商宣传的随机写入吞吐量)。请参见下面的图表以获取我的吞吐量测量结果。
我想知道是否有人知道为什么如果我有多个线程同时写入同一文件中的非重叠区域,我无法获得吞吐量增加?
我正在写入 2 GiB 的数据(随机写入),并且改变用于写入的线程数(从 1 到 16)。每个线程每次写入 4 KiB 的数据。我考虑了两种设置:(1)所有线程都写入一个文件,(2)每个线程都写入自己的文件。在开始基准测试之前,打开并使用
以下是机器的规格:
我已经包含了一个独立的C++程序,我已经在我的计算机上使用它来复现这个行为。我一直使用
O_DSYNC和O_DIRECT打开)。我注意到,如果线程同时写入单个文件,则当线程数增加时,实现的写入吞吐量不会增加(即,写入似乎是串行应用而非并行应用)。但是,如果每个线程都写入自己的文件,则可以获得吞吐量增加(高达SSD制造商宣传的随机写入吞吐量)。请参见下面的图表以获取我的吞吐量测量结果。
我想知道是否有人知道为什么如果我有多个线程同时写入同一文件中的非重叠区域,我无法获得吞吐量增加?
我正在写入 2 GiB 的数据(随机写入),并且改变用于写入的线程数(从 1 到 16)。每个线程每次写入 4 KiB 的数据。我考虑了两种设置:(1)所有线程都写入一个文件,(2)每个线程都写入自己的文件。在开始基准测试之前,打开并使用
fallocate() 将文件初始化为最终大小。文件使用 O_DIRECT 和 O_DSYNC 打开。将每个线程分配到文件中的随机不相交的偏移量子集(即,线程写入的区域不重叠)。然后,线程同时使用 pwrite() 写入这些偏移量。以下是机器的规格:
- Linux 5.9.1-arch1-1
- 1 TB 英特尔 NVMe 固态硬盘(型号 SSDPE2KX010T8)
- ext4 文件系统
- 128 GiB 内存
- 2.10 GHz 20 核 Xeon Gold 6230 CPU
我已经包含了一个独立的C++程序,我已经在我的计算机上使用它来复现这个行为。我一直使用
g++ -O3 -lpthread <file>进行编译(我正在使用g++版本10.2.0)。#include <algorithm>
#include <cassert>
#include <chrono>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <random>
#include <thread>
#include <vector>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
constexpr size_t kBlockSize = 4 * 1024;
constexpr size_t kDataSizeMiB = 2048;
constexpr size_t kDataSize = kDataSizeMiB * 1024 * 1024;
constexpr size_t kBlocksTotal = kDataSize / kBlockSize;
constexpr size_t kRngSeed = 42;
void AllocFiles(unsigned num_files, size_t blocks_per_file,
std::vector<int> &fds,
std::vector<std::vector<size_t>> &write_pos) {
std::mt19937 rng(kRngSeed);
for (unsigned i = 0; i < num_files; ++i) {
const std::string path = "f" + std::to_string(i);
fds.push_back(open(path.c_str(), O_CREAT | O_WRONLY | O_DIRECT | O_DSYNC,
S_IRUSR | S_IWUSR));
write_pos.emplace_back();
auto &file_offsets = write_pos.back();
int fd = fds.back();
for (size_t blk = 0; blk < blocks_per_file; ++blk) {
file_offsets.push_back(blk * kBlockSize);
}
fallocate(fd, /*mode=*/0, /*offset=*/0, blocks_per_file * kBlockSize);
std::shuffle(file_offsets.begin(), file_offsets.end(), rng);
}
}
void ThreadMain(int fd, const void *data, const std::vector<size_t> &write_pos,
size_t offset, size_t num_writes) {
for (size_t i = 0; i < num_writes; ++i) {
pwrite(fd, data, kBlockSize, write_pos[i + offset]);
}
}
int main(int argc, char *argv[]) {
assert(argc == 3);
unsigned num_threads = strtoul(argv[1], nullptr, 10);
unsigned files = strtoul(argv[2], nullptr, 10);
assert(num_threads % files == 0);
assert(num_threads >= files);
assert(kBlocksTotal % num_threads == 0);
void *data_buf;
posix_memalign(&data_buf, 512, kBlockSize);
*reinterpret_cast<uint64_t *>(data_buf) = 0xFFFFFFFFFFFFFFFF;
std::vector<int> fds;
std::vector<std::vector<size_t>> write_pos;
std::vector<std::thread> threads;
const size_t blocks_per_file = kBlocksTotal / files;
const unsigned threads_per_file = num_threads / files;
const unsigned writes_per_thread_per_file =
blocks_per_file / threads_per_file;
AllocFiles(files, blocks_per_file, fds, write_pos);
const auto begin = std::chrono::steady_clock::now();
for (unsigned thread_id = 0; thread_id < num_threads; ++thread_id) {
unsigned thread_file_offset = thread_id / files;
threads.emplace_back(
&ThreadMain, fds[thread_id % files], data_buf,
write_pos[thread_id % files],
/*offset=*/(thread_file_offset * writes_per_thread_per_file),
/*num_writes=*/writes_per_thread_per_file);
}
for (auto &thread : threads) {
thread.join();
}
const auto end = std::chrono::steady_clock::now();
for (const auto &fd : fds) {
close(fd);
}
std::cout << kDataSizeMiB /
std::chrono::duration_cast<std::chrono::duration<double>>(
end - begin)
.count()
<< std::endl;
free(data_buf);
return 0;
}