我正在通过DMS AWS服务将数据从RDS Postgres数据库迁移到S3,任务类型是全量加载和CDC(增量变更)。
假设现在我有一个名为employee的postgres表中的一些数据。例如: | emp_id | emp_name | |--------|----------| | 1 | John | | 2 | Angel |
当任务最初创建时,会进行全量加载,并在s3目标位置创建LOAD00000____.parquet文件。 现在我正在向表中插入另一行: | emp_id | emp_name | |--------|----------| | 3 | Ram |
现在发生了CDC操作,并创建了一个日期文件夹(20220101 /),其中包含一个parquet文件。
实际上,我想尽管在重新加载表后发生截断/删除操作,仍要保留目标中的表。
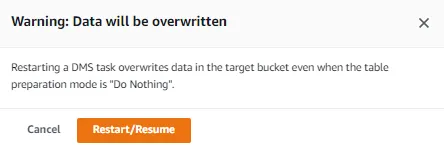
我在任务设置中有这些配置。期望在我截断/删除postgresql表并重新加载后,目标数据不应分别被截断/删除。然而,无论我在
我的task_setting.json文件也有:
假设现在我有一个名为employee的postgres表中的一些数据。例如: | emp_id | emp_name | |--------|----------| | 1 | John | | 2 | Angel |
当任务最初创建时,会进行全量加载,并在s3目标位置创建LOAD00000____.parquet文件。 现在我正在向表中插入另一行: | emp_id | emp_name | |--------|----------| | 3 | Ram |
现在发生了CDC操作,并创建了一个日期文件夹(20220101 /),其中包含一个parquet文件。
实际上,我想尽管在重新加载表后发生截断/删除操作,仍要保留目标中的表。
"ChangeProcessingDdlHandlingPolicy": {
"HandleSourceTableDropped": false,
"HandleSourceTableTruncated": false,
"HandleSourceTableAltered": false
}
我在任务设置中有这些配置。期望在我截断/删除postgresql表并重新加载后,目标数据不应分别被截断/删除。然而,无论我在
HandleSourceTableDropped和HandleSourceTableTruncated的配置键中给出的值是什么,目标文件夹都会被删除。我的task_setting.json文件也有:
"TargetTablePrepMode": "TRUNCATE_BEFORE_LOAD",
问题:
- 为什么在重新加载时S3文件夹会被删除?而且无论我为
ChangeProcessingDdlHandlingPolicy中的键提供哪些值(True / False)。 ChangeProcessingDdlHandlingPolicy这个配置对象是什么意思?