我需要帮助优化一个自定义的TensorFlow模型。我有一个40GB的ZLIB压缩的.TFRecords文件,其中包含我的训练数据。每个样本由两个384x512x3的图像和一个384x512x2的向量场组成。我正在按照以下方式加载我的数据:
num_threads = 16
reader_kwargs = {'options': tf.python_io.TFRecordOptions(tf.python_io.TFRecordCompressionType.ZLIB)}
data_provider = slim.dataset_data_provider.DatasetDataProvider(
dataset,
num_readers=num_threads,
reader_kwargs=reader_kwargs)
image_a, image_b, flow = data_provider.get(['image_a', 'image_b', 'flow'])
image_as, image_bs, flows = tf.train.batch(
[image_a, image_b, flow],
batch_size=dataset_config['BATCH_SIZE'], # 8
capacity=dataset_config['BATCH_SIZE'] * 10,
num_threads=num_threads,
allow_smaller_final_batch=False)
然而,我的全局步速仅为0.25-0.30(非常慢!)
这是我使用的并行读取器的TensorBoard仪表板,它始终保持在99%-100%。
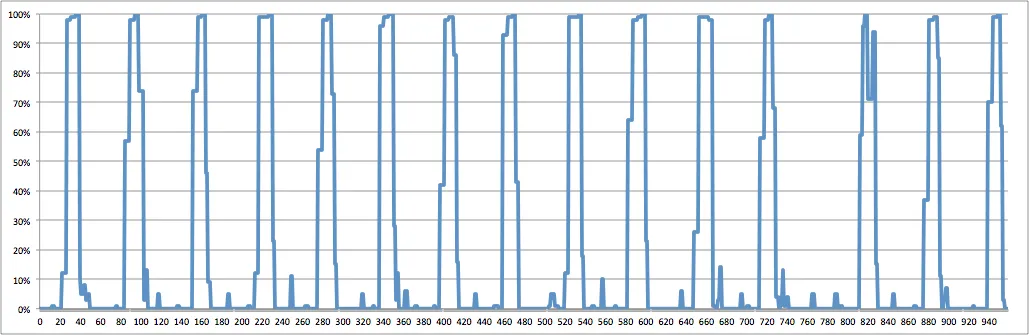
我将GPU使用率绘制成了随时间变化的图形(%每秒)。看起来数据不足,但我不知道该如何解决。我已经尝试过增加/减少线程数量,但似乎没有任何差别。我正在使用NVIDIA K80 GPU进行训练,拥有4个CPU和61GB的RAM。
如何使训练更快?