概要:
在所有场景中,IN和EXISTS的表现都相似。以下是用于验证的参数。
执行成本,时间:
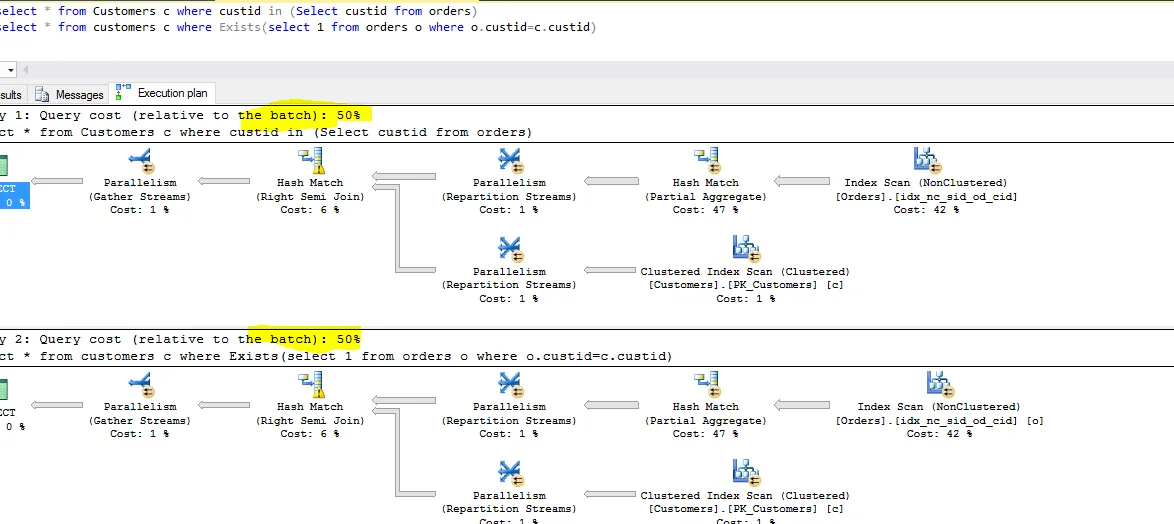
两者相同,优化器生成相同的计划。
内存授予:
这两个查询的内存授予相同。
CPU时间,逻辑读取:
Exists在CPU时间方面似乎比IN稍微好一点,尽管读取是相同的。
我对每个查询使用了以下测试数据集进行了10次运行。
- 非常大的子查询结果集(100000行)
- 重复行
- 空值行
对于上述所有情况,IN和EXISTS的表现方式都相同。
关于用于测试的性能V3数据库的一些信息。
有1000000个订单的20000个客户,因此每个客户在订单表中随机重复(在10到100范围内)。
执行成本,时间:
以下是两个查询运行的屏幕截图。观察每个查询的相对成本。
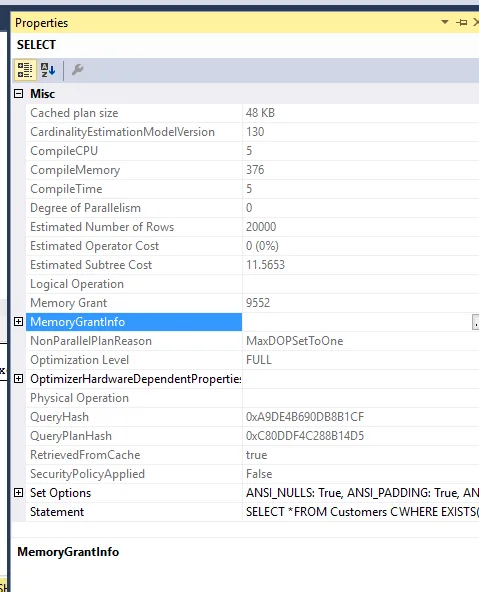
内存成本:
这两个查询的内存授予也是相同的。我强制使用MDOP 1,以便不将它们溢出到TEMPDB。
CPU时间,读取:
对于Exists:
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 469 ms, elapsed time = 595 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
对于IN:
(20000 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 547 ms, elapsed time = 669 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
在每种情况下,优化器都足够智能,可以重新排列查询语句。
我倾向于仅使用“
EXISTS”(我的意见)。使用“
EXISTS”的一个用例是当您不想返回第二个表结果集时。
根据Martin Smith的查询更新:
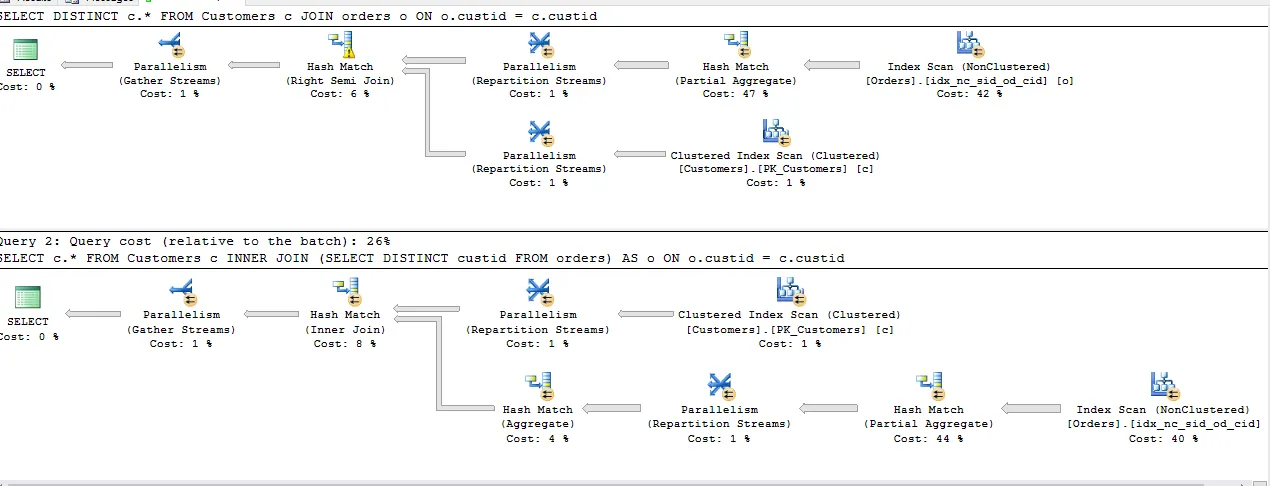
我运行了下面的查询,以找到从第一个表中获取存在于第二个表中引用的行的最有效方式。
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
SELECT *
FROM Customers C
WHERE EXISTS(SELECT 1 FROM Orders o WHERE o.custid = c.custid)
SELECT *
FROM Customers c
WHERE custid IN (SELECT custid FROM Orders)
所有上述查询的成本大体相同,除了第二个
INNER JOIN,其计划与其他查询相同。
< p >
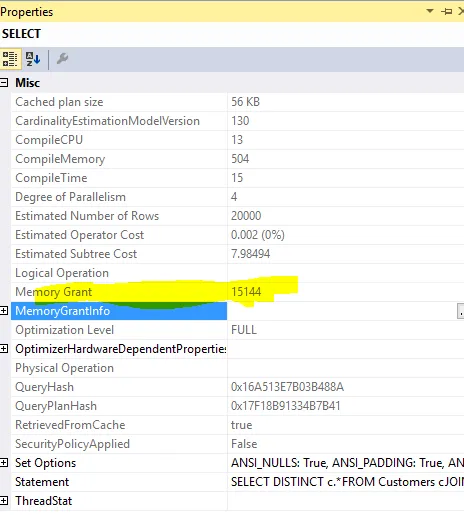
内存授予:
此查询
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
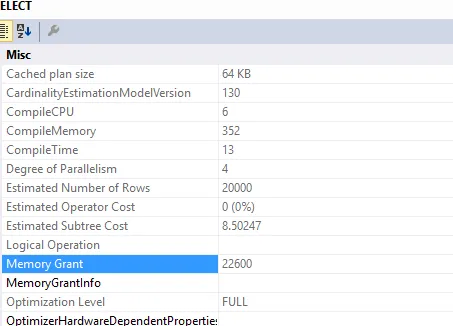
所需的内存授权
此查询
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
所需的内存授予量为...
CPU时间、读取次数:
对于查询:
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 48, logical reads 1344, physical reads 96, read-ahead reads 1248, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms, elapsed time = 781 ms.
查询:
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1499 ms, elapsed time = 403 ms.
inner join,不需要子查询。 - Marc Btable2返回列,并在存在多个匹配项时返回多行。它与EXISTS或IN不可互换。 - D Stanleyin还是exists会对选择产生任何影响。然而,对于NOT IN和NOT EXISTS来说,情况并非如此,因为它们可能具有不同的语义和性能。 - Martin Smith