fork()的最简单示例
printf("I'm printed once!\n");
fork();
printf("You see this line twice!\n");
fork()的返回值。返回值-1=失败;0=子进程;正数=父进程(返回值是子进程id)
pid_t id = fork();
if (id == -1) exit(1);
if (id > 0)
{
} else {
}
子进程和父进程有何不同之处?
- 父进程会在子进程结束时通过信号通知,但反过来则不会。
- 子进程不会继承未决信号或定时器警报。完整列表请参见fork()。
- 此处可以使用getpid()返回进程ID。父进程ID可以由getppid()返回。
现在让我们将您的程序代码可视化
pid_t pid;
pid = fork();
现在操作系统会为父进程和子进程分别创建两个完全相同的地址空间副本。
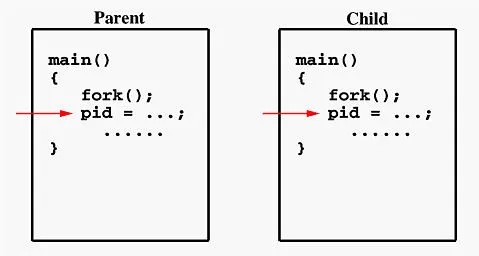
父进程和子进程在系统调用fork()后开始执行。由于两个进程具有相同但分离的地址空间,因此在fork()调用之前初始化的那些变量在两个地址空间中具有相同的值。每个进程都有自己的地址空间,所以任何修改都将独立于其他进程。如果父进程更改其变量的值,则修改仅会影响父进程地址空间中的变量。由fork()系统调用创建的其他地址空间不会受到影响,即使它们具有相同的变量名称。
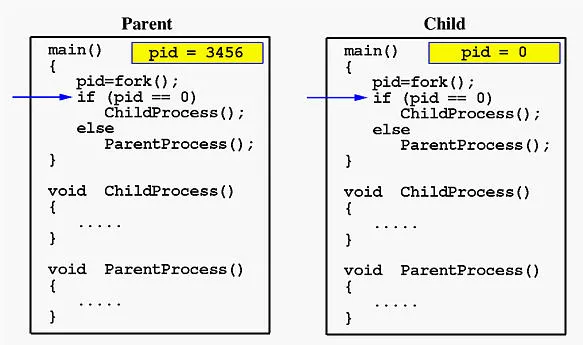
父进程的pid不为零,它调用函数ParentProcess()。另一方面,子进程的pid为零,它调用ChildProcess()如下所示:
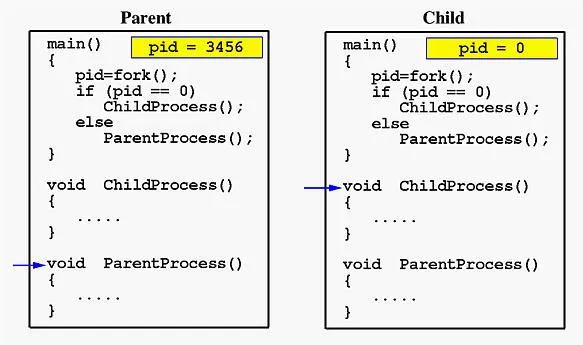
在您的代码中,父进程调用
wait(),在该点暂停,直到子进程退出。因此,子进程的输出会先出现。
if (pid == 0) {
// The child runs this part because fork returns 0 to the child
for (i = 0; i < SIZE; i++) {
nums[i] *= -i;
printf("CHILD: %d ",nums[i]); /* LINE X */
}
}
子进程的输出
第 X 行的输出内容
CHILD: 0 CHILD: -1 CHILD: -4 CHILD: -9 CHILD: -16
当子进程退出后,父进程从等待(wait())调用之后继续执行并打印其输出。
else if (pid > 0) {
wait(NULL);
for (i = 0; i < SIZE; i++)
printf("PARENT: %d ",nums[i]);
}
来自父进程的输出:
在Y行输出什么
PARENT: 0 PARENT: 1 PARENT: 2 PARENT: 3 PARENT: 4
最后,子进程和父进程合并的输出将如下显示在终端上:
CHILD: 0 CHILD: -1 CHILD: -4 CHILD: -9 CHILD: -16 PARENT: 0 PARENT: 1 PARENT: 2 PARENT: 3 PARENT: 4
了解更多信息,请参考此链接
man fork是一个 Linux 系统调用,用于创建一个新的进程作为原始进程的副本。子进程将获得与父进程相同的代码、数据和堆栈,并从父进程那里继承打开的文件和其他系统资源。在成功调用fork()后,父进程和子进程在不同的地址空间中运行,并且具有不同的进程 ID。子进程从fork()返回0,而父进程则返回子进程的进程 ID。 - RageDprintf()语句的末尾放置换行符,否则可能什么都不会显示。您应该使用#include <sys/wait.h>来声明wait()函数;您可能不需要显式地使用#include <sys/types.h>。 - Jonathan Leffler