如何快速找到向量或列中第二(第三...)大/小值的索引?
即,如何找到:
sort(x,partial=n-1)[n-1]
max()
但是对于
which.max()
最好的祝福,
如何快速找到向量或列中第二(第三...)大/小值的索引?
即,如何找到:
sort(x,partial=n-1)[n-1]
max()
但是对于
which.max()
最好的祝福,
一种可能的方法是使用sort函数的index.return参数。不过我不确定这是否是最快的方法。
set.seed(21)
x <- rnorm(10)
ind <- 2
sapply(sort(x, index.return=TRUE), `[`, length(x)-ind+1)
# x ix
# 1.746222 3.000000
编辑2:
正如Joshua指出的那样,当您在最大值上出现平局时,所提供的解决方案都不正确,因此:
X <- c(11:19,19)
n <- length(unique(X))
which(X == sort(unique(X),partial=n-1)[n-1])
那么做得正确最快的方法。我删除了那种方式,因为它不起作用并且速度较慢,因此根据OP的说法,这不是一个好的答案。
为了指出我们遇到的问题:
> X <- c(11:19,19)
> n <- length(X)
> which(X == sort(X,partial=n-1)[n-1])
[1] 9 10 #which is the indices of the double maximum 19
> n <- length(unique(X))
> which(X == sort(unique(X),partial=n-1)[n-1])
[1] 8 # which is the correct index of 18
有效解决方案的计时:
> x <- runif(1000000)
> ind <- 2
> n <- length(unique(x))
> system.time(which(x == sort(unique(x),partial=n-ind+1)[n-ind+1]))
user system elapsed
0.11 0.00 0.11
> system.time(sapply(sort(unique(x), index.return=TRUE), `[`, n-ind+1))
user system elapsed
0.69 0.00 0.69
order() 给出向量按升序/降序排列的排列方式。它之所以在这里起作用是因为 x 已经排序好了,但如果没有排序,order(x, decreasing = TRUE)[i] 应该就足够找到第 i 大的元素了。或者我错得很尴尬吗? - Gavin Simpson图书馆Rfast已经实现了具有返回索引选项的第n个元素函数。
更新(2021年2月28日)包套件提供了更快的实现方法(topn),如下面的模拟所示。
x <- runif(1e+6)
n <- 2
which_nth_highest_richie <- function(x, n)
{
for(i in seq_len(n - 1L)) x[x == max(x)] <- -Inf
which(x == max(x))
}
which_nth_highest_joris <- function(x, n)
{
ux <- unique(x)
nux <- length(ux)
which(x == sort(ux, partial = nux - n + 1)[nux - n + 1])
}
microbenchmark::microbenchmark(
topn = kit::topn(x, n,decreasing = T)[n],
Rfast = Rfast::nth(x,n,descending = T,index.return = T),
order = order(x, decreasing = TRUE)[n],
richie = which_nth_highest_richie(x,n),
joris = which_nth_highest_joris(x,n))
Unit: milliseconds
expr min lq mean median uq max neval
topn 3.741101 3.7917 4.517201 4.060752 5.108901 7.403901 100
Rfast 15.8121 16.7586 20.64204 17.73010 20.7083 47.6832 100
order 110.5416 113.4774 120.45807 116.84005 121.2291 164.5618 100
richie 22.7846 24.1552 39.35303 27.10075 42.0132 179.289 100
joris 131.7838 140.4611 158.20704 156.61610 165.1735 243.9258 100
在一百万个数字中找到第二大的值的索引,Topn是明显的赢家。
此外,进行了模拟以估计查找不同n的第n大数字的运行时间。 对于每个n,变量x都被重新填充,但其大小始终为一百万个数字。
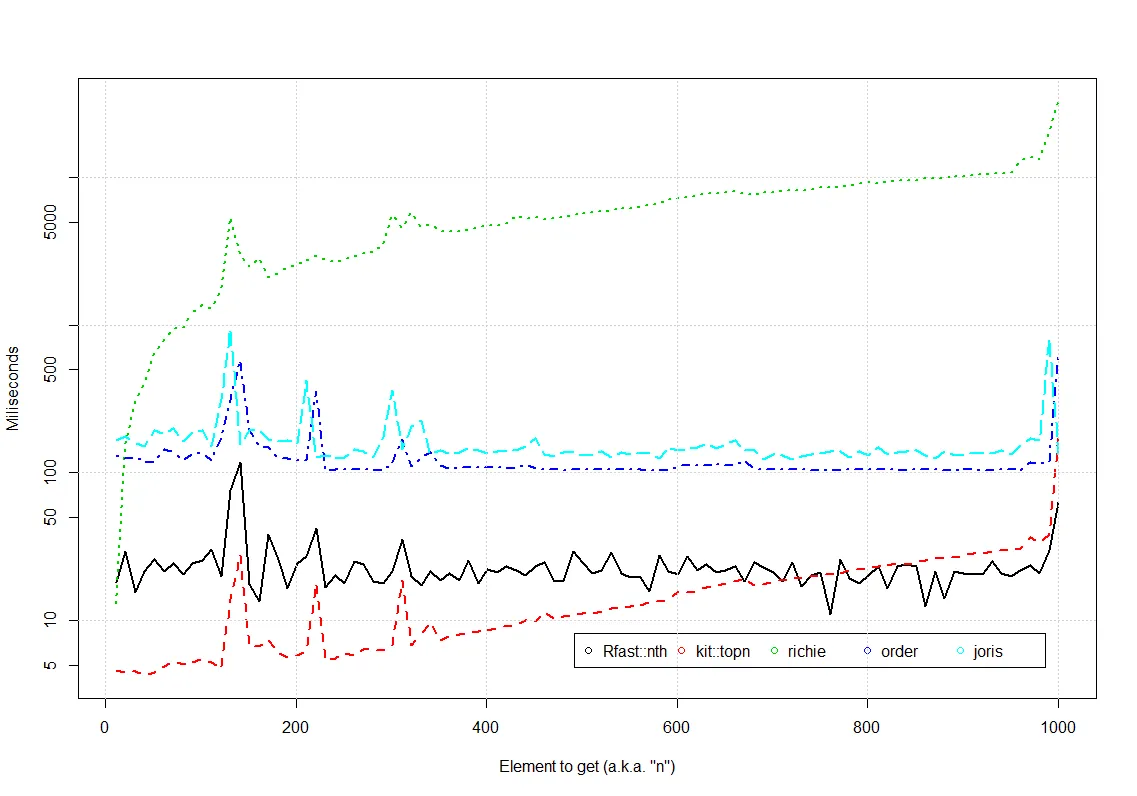
如图所示,当n不太大时,Topn是查找第n大元素及其索引的最佳选择。我们可以观察到,在图中,对于更大的n,topn比Rfast的nth慢。 值得注意的是,topn没有实现n > 1000,这种情况下会抛出错误。
kit::topn。我在OP提供的链接中给出了解决方案。Rfast不是最快的解决方案。 - Suresh_Patel方法:将所有的最大值设置为-Inf,然后找到最大值的索引。不需要排序。
X <- runif(1e7)
system.time(
{
X[X == max(X)] <- -Inf
which(X == max(X))
})
可以使用绑带来提高速度。
如果您能保证没有绑带,那么更快的版本是
system.time(
{
X[which.max(X)] <- -Inf
which.max(X)
})
编辑:正如Joris所提到的,这种方法在查找第三、第四等最高值时并不那么有效。
which_nth_highest_richie <- function(x, n)
{
for(i in seq_len(n - 1L)) x[x == max(x)] <- -Inf
which(x == max(x))
}
which_nth_highest_joris <- function(x, n)
{
ux <- unique(x)
nux <- length(ux)
which(x == sort(ux, partial = nux - n + 1)[nux - n + 1])
}
使用 x <- runif(1e7) 和 n = 2,Richie 获胜。
system.time(which_nth_highest_richie(x, 2)) #about half a second
system.time(which_nth_highest_joris(x, 2)) #about 2 seconds
n = 100,Joris 获胜。system.time(which_nth_highest_richie(x, 100)) #about 20 seconds, ouch!
system.time(which_nth_highest_joris(x, 100)) #still about 2 seconds
平衡点,即它们花费相同时间的位置,大约在 n = 10。
which()函数。将sort()函数的输出结果与which()函数结合使用,以找到与sort()步骤的输出匹配的索引。> set.seed(1)
> x <- sample(1000, 250)
> sort(x,partial=n-1)[n-1]
[1] 992
> which(x == sort(x,partial=n-1)[n-1])
[1] 145
处理并列值 上述解决方案在存在并列值且这些值是第i大或更大的值时不起作用(也不是预期的)。在对这些值进行排序之前,我们需要对向量中的唯一值进行处理,然后上述解决方案就可以正常工作:
> set.seed(1)
> x <- sample(1000, 1000, replace = TRUE)
> length(unique(x))
[1] 639
> n <- length(x)
> i <- which(x == sort(x,partial=n-1)[n-1])
> sum(x > x[i])
[1] 0
> x.uni <- unique(x)
> n.uni <- length(x.uni)
> i <- which(x == sort(x.uni, partial = n.uni-1)[n.uni-1])
> sum(x > x[i])
[1] 2
> tail(sort(x))
[1] 994 996 997 997 1000 1000
order() 在这里也非常有用:
> head(ord <- order(x, decreasing = TRUE))
[1] 220 145 209 202 211 163
所以这里的解决方案是ord[2],它代表数组x中第二高/大元素的索引。
一些计时:
> set.seed(1)
> X <- sample(1e7, 1e7)
> system.time({n <- length(X); which(X == sort(X, partial = n-1)[n-1])})
user system elapsed
0.319 0.058 0.378
> system.time({ord <- order(X, decreasing = TRUE); ord[2]})
user system elapsed
14.578 0.084 14.708
> system.time({order(X, decreasing = TRUE)[2]})
user system elapsed
14.647 0.084 14.779
但是,如链接的帖子所述并且上面的时间表显示,order()速度较慢,但两者提供相同的结果:
> all.equal(which(X == sort(X, partial = n-1)[n-1]),
+ order(X, decreasing = TRUE)[2])
[1] TRUE
对于处理关系的版本:
foo <- function(x, i) {
X <- unique(x)
N <- length(X)
i <- i-1
which(x == sort(X, partial = N-i)[N-i])
}
> system.time(foo(X, 2))
user system elapsed
1.249 0.176 1.454
因此,这些额外的步骤会稍微降低这种解决方案的速度,但它仍然与order()非常有竞争力。
这是我找到向量中前N个最高值索引的解决方案(不完全符合原始发布者的要求,但这可能对其他人有所帮助)
index.top.N = function(xs, N=10){
if(length(xs) > 0) {
o = order(xs, na.last=FALSE)
o.length = length(o)
if (N > o.length) N = o.length
o[((o.length-N+1):o.length)]
}
else {
0
}
}
kit::topn将是最明显最快的解决方案。 - Suresh_Patel