对于足够大的文件,使用基于Numba的方法可能更加高效:
import numba as nb
@nb.njit
def process(
block,
n,
last_nl_pos,
nl_pos,
nl_count,
offset,
nl=ord("\n")
):
nl = ord("\n")
for i, c in enumerate(block, offset):
if c == nl:
found = True
last_nl_pos = nl_pos
nl_pos = i
nl_count += 1
if nl_count == n:
break
return last_nl_pos, nl_pos, nl_count
def read_nth_line_nb(
filepath: str,
n: int,
encoding="utf-8",
size=2 ** 22,
) -> str:
with open(filepath, "rb") as file_obj:
last_nl_pos = nl_pos = -1
nl_count = -1
offset = 0
while True:
block = file_obj.read(size)
if block:
last_nl_pos, nl_pos, nl_count = process(
block, n, last_nl_pos, nl_pos, nl_count, offset
)
offset += size
if nl_count == n:
file_obj.seek(last_nl_pos + 1)
return file_obj.read(nl_pos - last_nl_pos).decode(encoding)
else:
return
这个过程基本上是分块处理文件,跟踪新行出现的数量和位置(以及该块在文件中的位置)。
为了进行比较,我使用itertools.islice()方法:
import itertools
def read_nth_line_isl(filepath: str, n: int, encoding="utf-8") -> str:
with open(filepath, "r", encoding=encoding) as file_obj:
return next(itertools.islice(file_obj, n, n + 1), None)
除了简单的循环外:
def read_nth_line_loop(filepath: str, n: int, encoding="utf-8") -> str:
with open(filepath, "r", encoding=encoding) as file_obj:
for i, line in enumerate(file_obj):
if i == n:
return line
return None
假设有一些文件是使用以下方式创建的:
import random
import string
def write_some_file(filepath: str, n: int, m: int = 10, l: int = 100, encoding="utf-8") -> None:
with open(filepath, "w", encoding=encoding) as file_obj:
for i in range(n):
line = "".join(random.choices(string.ascii_letters, k=random.randrange(m, l)))
file_obj.write(f"{i:0{k}d} - {line}\n")
k = 9
for i in range(1, k):
n_max = 10 ** i
print(n_max)
write_some_file(f"test{n_max:0{k}d}.txt", n_max)
可以进行测试以确认它们是否给出相同的结果:
funcs = read_nth_line_isl, read_nth_line_loop, read_nth_line_nb
k = 9
n_max = 10 ** 5
filename = f"test{n_max:0{k}d}.txt"
for func in funcs:
print(f"{func.__name__:>20} {func(filename, n_max - 1)!r}")
计算时间可以使用以下方式:
k = 9
timings = {}
for i in range(1, k - 1):
n_max = 10 ** i
filename = f"test{n_max:0{k}d}.txt"
print(filename)
timings[i] = []
base = funcs[0](filename, n_max - 1)
for func in funcs:
res = func(filename, n_max - 1)
is_good = base == res
if i < 6:
timed = %timeit -r 12 -n 12 -q -o func(filename, n_max - 1)
else:
timed = %timeit -r 1 -n 1 -q -o func(filename, n_max - 1)
timing = timed.best * 1e3
timings[i].append(timing if is_good else None)
print(f"{func.__name__:>24} {is_good!s:5} {timing:10.3f} ms")
并绘制为:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(data=timings, index=[func.__name__ for func in funcs]).transpose()
df.plot(marker='o', xlabel='log₁₀(Input Size) / #', ylabel='Best timing / µs', figsize=(6, 4), logy=True)
fig = plt.gcf()
fig.patch.set_facecolor('white')
获得:
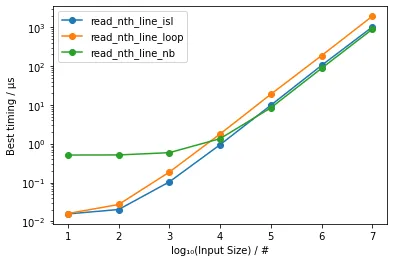
表明对于足够大的输入(超过10⁵),基于Numba的方法略微更快(约5-15%)。