我花了一些时间学习正则表达式,但我仍然不明白以下技巧如何工作,可以匹配不同顺序的两个单词。
import re
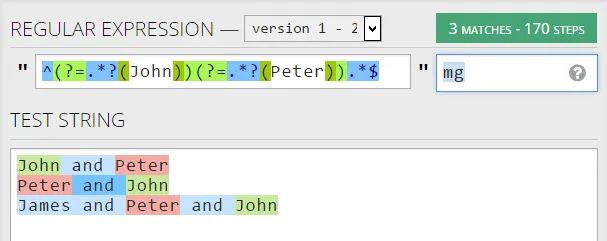
reobj = re.compile(r'^(?=.*?(John))(?=.*?(Peter)).*$',re.MULTILINE)
string = '''
John and Peter
Peter and John
James and Peter and John
'''
re.findall(reobj,string)
result
[('John', 'Peter'), ('John', 'Peter'), ('John', 'Peter')]
(https://www.regex101.com/r/qW4rF4/1)
我知道(?=.* )这部分被称为正向预查,但它在这种情况下是如何工作的?
有什么解释吗?