两个问题:
- 浏览器是否像JavaScript一样内置了CSS解释器?
- 浏览器什么时候读取CSS以及何时应用CSS?
具体来说,我想澄清JavaScript和CSS之间的区别或原因,即您需要专门等到window.onload以使解释器能够正确地getElementById。但是,在CSS中,您可以随意选择和应用样式类和ID。
(如果这有任何影响,请假设我指的是在头部拥有外部样式表的基本HTML页面)
所有这些渲染引擎都包含CSS解释器和HTML DOM解析器。
所有这些引擎都遵循以下列出的模型,这些是W3C标准的一部分。
注意:所有这些模型都相互关联且相互依赖。它们不是定义呈现CSS标准的单独模型。这些模型阐明了如何基于优先级(例如内联样式、特定性等)处理CSS。
阶段 1:

阶段2:
第三阶段:
注意:如果您尝试在缓慢的连接上打开任何网页,则可以清楚地观察到此阶段。为了获得更好的用户体验,大多数现代浏览器会尽快显示元素。这给用户留下了印象,即页面正在加载并且必须等待完成。
来源 HTML5 Rocks
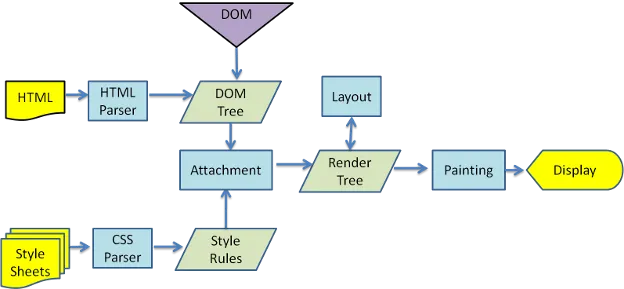
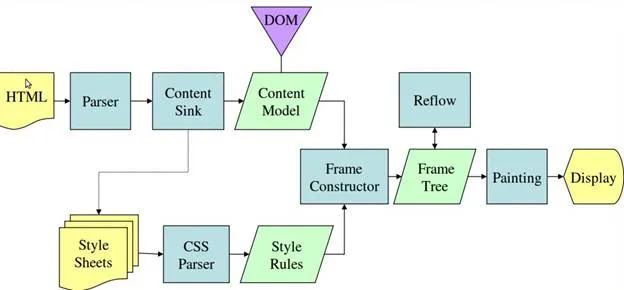
如果您最近使用过较慢的连接,您会发现随着DOM结构加载,CSS将应用于元素,并实际重新排列页面内容。由于CSS不是一种编程语言,它不依赖于在特定时间可用的对象来正确解析(JavaScript),因此浏览器可以通过为新元素应用样式来重新评估页面结构以检索更多HTML。
也许这就是为什么即使是今天,移动Safari的瓶颈并非始终是3G连接,而是页面渲染。
是的,浏览器内置了CSS解释器。你不需要“等待window.onload”的原因是:尽管JavaScript是一种图灵完备的命令式编程语言,但CSS只是一组样式规则,浏览器会将它们应用于匹配的元素。
.item h4,循环遍历所有HTML元素,然后应用样式,然后继续下一个CSS选择器吗?还是先解析HTML,然后循环遍历CSS选择器,匹配.item h4,然后移动到下一个元素? - chharveyCSS解析器
与HTML不同,CSS是一个无上下文语法(带有确定性语法)。
因此,我们将有CSS规范定义CSS词法和语法语法,
解析器通过样式表进行应用。
每个标记的词汇语法由正则表达式定义:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
语法规则在BNF中描述。
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator selector ] ]
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
如果您想了解浏览器工作流程的详细描述,请查看此文章。
我相信浏览器会按照它找到的顺序解释CSS,这样在body中的CSS(内联)优先于head中的CSS(包括外部CSS)。