高级编程语言通常提供一个函数来确定浮点数的绝对值。例如,在C标准库中,有fabs(double)函数。
这个库函数在x86目标上是如何实现的?当我调用这样一个高级函数时,底层会发生什么?
这是一个昂贵的操作(乘法和平方根的组合)吗?还是通过从内存中删除负号来找到结果?
高级编程语言通常提供一个函数来确定浮点数的绝对值。例如,在C标准库中,有fabs(double)函数。
这个库函数在x86目标上是如何实现的?当我调用这样一个高级函数时,底层会发生什么?
这是一个昂贵的操作(乘法和平方根的组合)吗?还是通过从内存中删除负号来找到结果?
总的来说,计算浮点数的绝对值是一项非常便宜和快速的操作。
在几乎所有情况下,您可以将标准库中的 fabs 函数视为黑匣子,在必要时将其添加到算法中,而不需要担心它如何影响执行速度。
如果您想了解为什么这是一项便宜的操作,则需要了解一些有关浮点值表示方式的知识。虽然 C 和 C++ 语言标准实际上并未强制执行它,但大多数实现遵循 IEEE-754 标准。在该标准中,每个浮点值的表示都包含一个称为符号位的位,用于标记该值是正还是负。例如,考虑一个 double,它是一个64位的双精度浮点值:
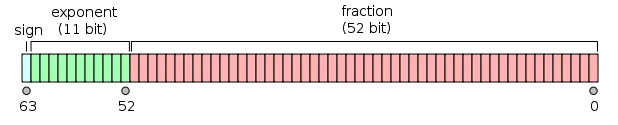
(图片由Codekaizen通过维基百科提供,根据CC-bySA许可证授权。)
您可以在最左边看到标志位,呈浅蓝色。这对于IEEE-754中所有浮点数精度都是正确的。因此,取绝对值基本上只需要在内存中翻转一个字节的值的表示。特别地,您只需要屏蔽掉符号位(按位与),强制它为0,从而成为无符号的。
假设您的目标体系结构具有硬件支持浮点运算,这通常是单个、一周期指令,基本上就像可能的一样快。优化编译器将内联调用fabs库函数,以其位置发出单个硬件指令。
fabs函数的开销,但是在最坏的情况下,该函数的实现只涉及从内存读取字节,屏蔽掉符号位,并将结果存回内存。fabs的调用转换为机器码。fabs指令(是的,和C函数同名)。这将从x87寄存器堆栈顶部的浮点值中去除符号位(如果存在)。在AMD处理器和Intel Pentium 4上,fabs是一个1周期指令,具有2个周期的延迟。在AMD Ryzen和所有其他Intel处理器上,这是一个1周期指令,具有1个周期的延迟。ANDPS指令*,它恰好执行了上述操作:对浮点值进行按位与运算,并使用常量掩码屏蔽掉符号位。请注意,SSE2没有专用于取绝对值的指令,而是使用多功能的按位操作指令来完成该任务。执行时间(周期、延迟等特性)在不同处理器微架构之间有所差异,但通常具有1-3个周期的吞吐量和类似的延迟。如果您愿意,可以在Agner Fog's instruction tables中查找感兴趣的处理器信息。fabs确切地执行了我描述的操作,这是最好的通用解决方案。
__
* 技术上,这可能也是 ANDPD,其中 D 表示“double”(而 S 表示“single”),但 ANDPD 需要 SSE2 支持。SSE 支持单精度浮点运算,可追溯到 Pentium III。SSE2 对于双精度浮点运算是必需的,并从 Pentium 4 开始引入。x86-64 CPU 上始终支持 SSE2。使用 ANDPS 还是 ANDPD 是编译器优化器做出的决策;有时您会看到在双精度浮点值上使用 ANDPS,因为它只需要正确编写掩码。
此外,在支持 AVX 指令的 CPU 上,通常会在 ANDPS/ANDPD 指令上使用 VEX 前缀,使其变成 VANDPS/VANDPD。关于它的工作原理和目的的详细信息可以在其他地方在线找到;简而言之,混合使用 VEX 和非-VEX 指令可能会导致性能损失,因此编译器会尽量避免。不过,这两个版本都具有相同的效果和几乎相同的执行速度。
Oh, and because SSE is a SIMD instruction set, it is possible to compute the absolute value of multiple floating-point values at once. This, as you might imagine, is especially efficient. Compilers with auto-vectorization capabilities will generate code like this where possible. Example (mask can either be generated on-the-fly, as shown here, or loaded as a constant):
cmpeqd xmm1, xmm1 ; generate the mask (all 1s) in a temporary register
psrld xmm1, 1 ; put 1s in but the left-most bit of each packed dword
andps xmm0, xmm1 ; mask off sign bit in each packed floating-point value
_mm_uninitialized_ps();而不是实际支持的_mm_undefined_ps();。 - Peter Cordesconst __m128 absmask = _mm_castsi128_ps(_mm_set1_epi32(~(1<<31)); 应该是一个局部变量。这只是另一种编写 _mm_set1_ps(-0.0f) 的方式,以防您更愿意考虑位模式并且不想担心使用 -ffast-math 编译时编译器会如何处理负零。它仍应在内存中共享相同的文字常量。我写下这个答案已经将近两年了,当时我还不知道那么多。完全同意这只在编译器不能/不会内联某些内容的奇怪情况下才有很大作用,但您可以在循环之前即时生成。 - Peter Cordesfabs以这种方式运作是很合理的。8087是第一款实现IEEE 754的CPU(实际上,它是早期的草案;英特尔在起草和推动这个标准方面发挥了重要作用)。但是,CPU可能以不同的方式表示FP值,这就需要不同的fabs实现。这就是为什么最初的问题陈述存在问题(太广泛),我将范围缩小到x86,希望能够重新开放(成功!)。 - Cody Gray
fabs()或者abs()的实现尝试这样做,我会感到非常惊讶。 - ad absurdumANDPD指令来实现(基本上是对浮点数进行按位与操作)。这是一个相当快的指令,通常只需要1个时钟周期。 - Simon Byrne