我正在尝试编写一个程序,它可以接收一个指示路径的点列表和一个所需标记数,然后应将这些标记沿路径完全均匀地分布。由于路径是循环的,但给定任意起点和终点,我不认为它会影响算法。
第一步是将线段长度相加以确定路径的总长度,然后将其除以标记数以获得标记之间的期望距离。足够简单。
下一步是沿着路径行走,每次穿过另一个标记距离的偶数倍时存储每个标记的坐标。
在我的代码中,遍历似乎是正确的,但标记的分布不均匀,也没有完全遵循路径。 我已经在matplotlib中创建了一个可视化,显示标记落在哪里(请参见最后一部分)。
路径数据
point_data = [
(53.8024, 50.4762), (49.5272, 51.8727), (45.0118, 52.3863), (40.5399, 53.0184), (36.3951, 54.7708),
(28.7127, 58.6807), (25.5306, 61.4955), (23.3828, 65.2082), (22.6764, 68.3316), (22.6945, 71.535),
(24.6674, 77.6427), (28.8279, 82.4529), (31.5805, 84.0346), (34.7024, 84.8875), (45.9183, 84.5739),
(57.0529, 82.9846), (64.2141, 79.1657), (71.089, 74.802), (76.7944, 69.8429), (82.1092, 64.4783),
(83.974, 63.3605), (85.2997, 61.5455), (85.7719, 59.4206), (85.0764, 57.3729), (82.0979, 56.0247),
(78.878, 55.1062), (73.891, 53.0987), (68.7101, 51.7283), (63.6943, 51.2997), (58.6791, 51.7438),
(56.1255, 51.5243), (53.8024, 50.4762), (53.8024, 50.4762)]
遍历
import math
number_of_points = 20
def euclid_dist(x1, y1, x2, y2):
return ((x1-x2)**2 + (y1-y2)**2)**0.5
def move_point(x0, y0, d, theta_rad):
return x0 + d*math.cos(theta_rad), y0 + d*math.sin(theta_rad)
total_dist = 0
for i in range(1, len(point_data), 1):
x1, y1 = point_data[i - 1]
x2, y2 = point_data[i]
total_dist += euclid_dist(x1, y1, x2, y2)
dist_per_point = total_dist / number_of_points
length_left_over = 0 # distance left over from the last segment
# led_id = 0
results = []
for i in range(1, len(point_data), 1):
x1, y1 = point_data[i - 1]
x2, y2 = point_data[i]
angle_rads = math.atan2(y1-y2, x1-x2)
extra_rotation = math.pi / 2 # 90deg
angle_output = math.degrees((angle_rads + extra_rotation + math.pi) % (2*math.pi) - math.pi)
length_of_segment = euclid_dist(x1, y1, x2, y2)
distance_to_work_with = length_left_over + length_of_segment
current_dist = dist_per_point - length_left_over
while distance_to_work_with > dist_per_point:
new_point = move_point(x1, y1, current_dist, angle_rads)
results.append((new_point[0], new_point[1], angle_output))
current_dist += dist_per_point
distance_to_work_with -= dist_per_point
length_left_over = distance_to_work_with
可视化代码
import matplotlib.pyplot as plt
from matplotlib import collections as mc
import numpy as np
X = np.array([x for x, _, _ in results])
Y = np.array([y for _, y, _ in results])
plt.scatter(X, Y)
for i, (x, y) in enumerate(zip(X, Y)):
plt.text(x, y, str(i), color="red", fontsize=12)
possible_colors = [(1, 0, 0, 1), (0, 1, 0, 1), (0, 0, 1, 1)]
lines = []
colors = []
for i in range(len(point_data) -1 , 0, -1):
x1, y1 = point_data[i - 1]
x2, y2 = point_data[i]
lines.append(((x1, y1), (x2, y2)))
colors.append(possible_colors[i % 3])
lc = mc.LineCollection(lines, colors = colors, linewidths=2)
fig, ax = plt.subplots()
ax.add_collection(lc)
ax.autoscale()
ax.margins(0.1)
plt.show()
可视化结果
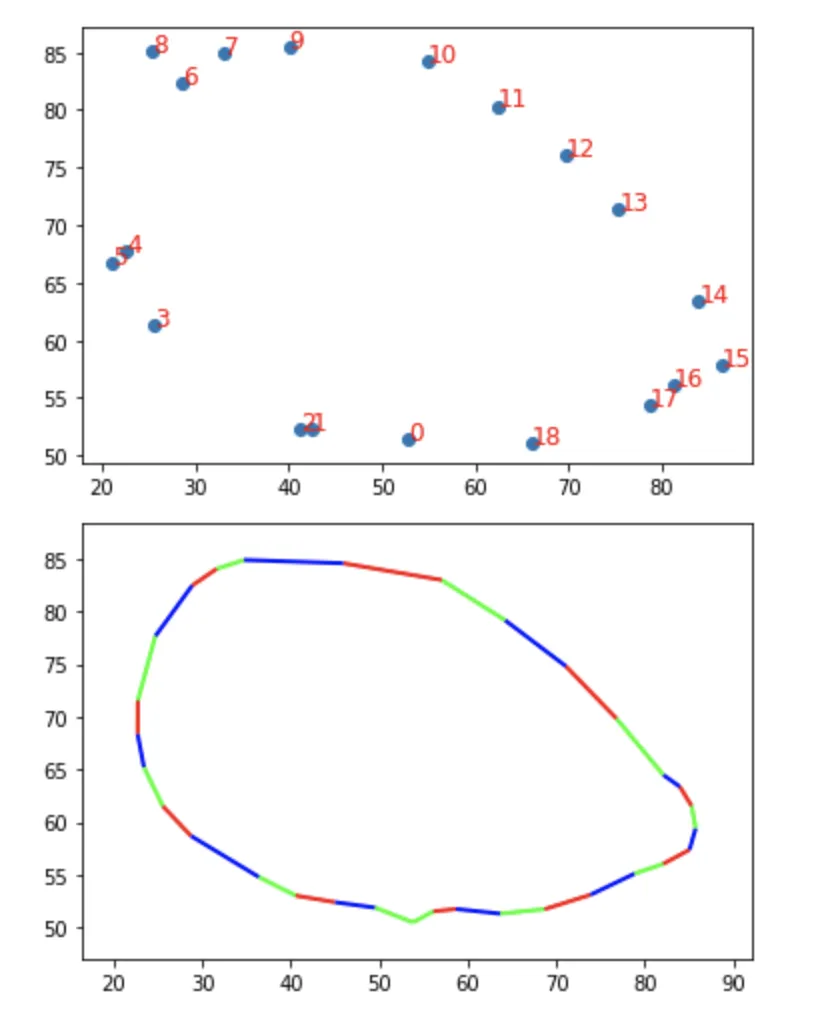
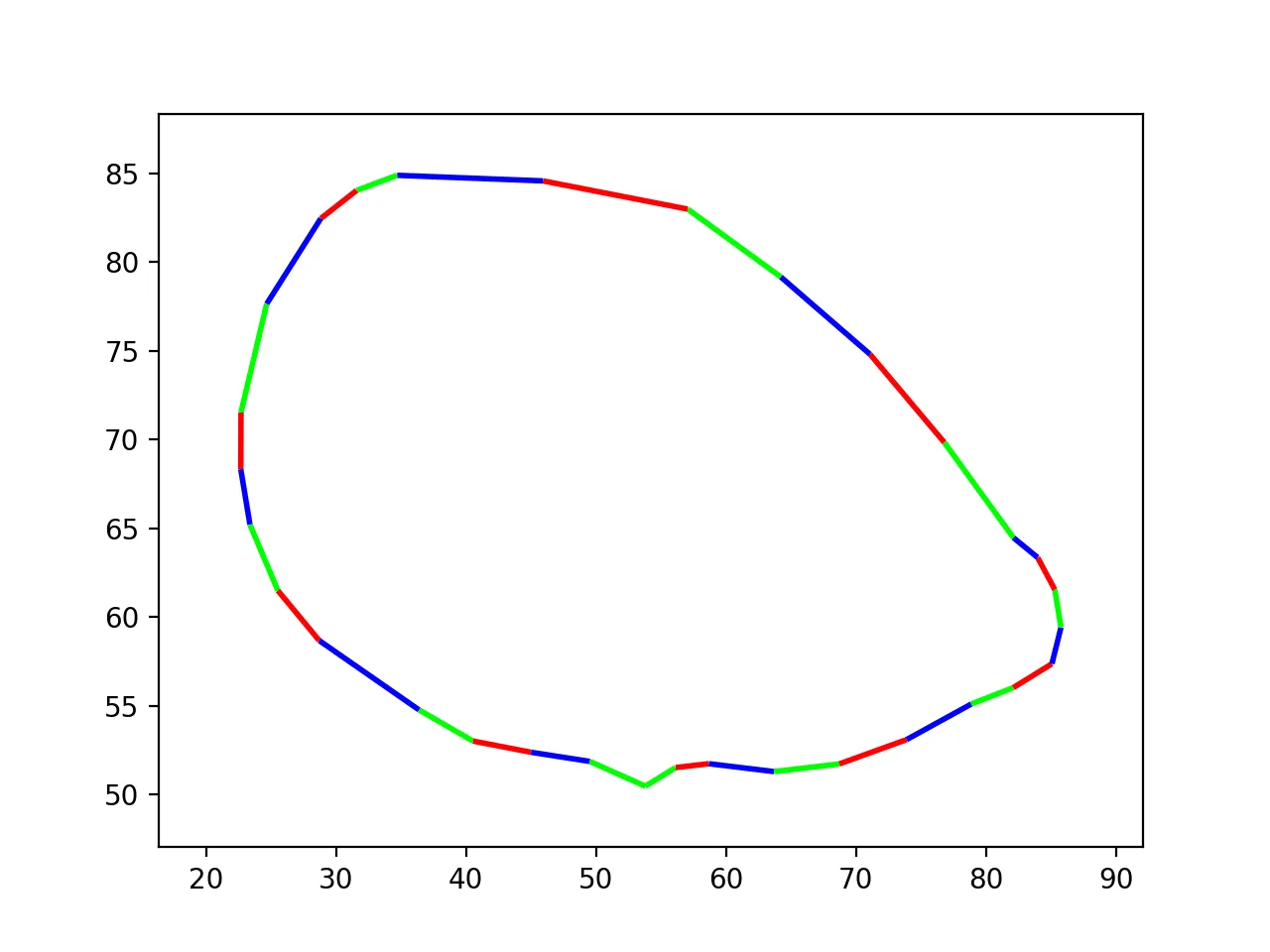
point1 = (x1, y1)和point2 = (x2, y2)相距5.0个单位,单位向量为((x2-x1) / 5.0, (y2-y1) / 5.0)。结果是一个指向从point1到point2方向的向量,并具有单位长度。从point1开始,向point2移动4.1个单位时,新点为x = x1 + 4.1 * (x2-x1)/5.0和y = y1 + 4.1 * (x2-x1)/5.0。也称为线性插值,这允许沿路径移动而无需三角函数。 - user3386109