我有一个PySpark DataFrame,想在对两列
一个客户可能与一个地址相关联多个订单,我想要获取一个
我的方法是创建一个窗口并按照
CUSTOMER_ID 和 ADDRESS_ID 进行groupBy之后,获得 ORDERED_TIME (DateTime字段,格式为 yyyy-mm-dd)的第二个最高值。一个客户可能与一个地址相关联多个订单,我想要获取一个
(customer,address) 对的第二个最近的订单。我的方法是创建一个窗口并按照
CUSTOMER_ID 和 ADDRESS_ID 进行分区,并按照 ORDERED_TIME 排序。sorted_order_times = Window.partitionBy("CUSTOMER_ID", "ADDRESS_ID").orderBy(col('ORDERED_TIME').desc())
df2 = df2.withColumn("second_recent_order", (df2.select("ORDERED_TIME").collect()[1]).over(sorted_order_times))
然而,我遇到了一个错误,显示ValueError: 'over' is not in list
是否有任何建议解决这个问题的正确方法?
如果需要其他信息,请告诉我。
示例数据
+-----------+----------+-------------------+
|USER_ID |ADDRESS_ID| ORDER DATE |
+-----------+----------+-------------------+
| 100| 1000 |2021-01-02 |
| 100| 1000 |2021-01-14 |
| 100| 1000 |2021-01-03 |
| 100| 1000 |2021-01-04 |
| 101| 2000 |2020-05-07 |
| 101| 2000 |2021-04-14 |
+-----------+----------+-------------------+
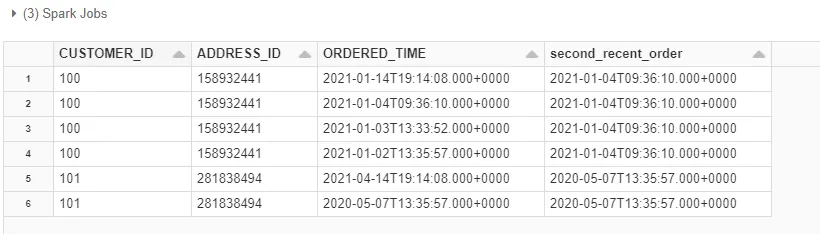
预期输出
+-----------+----------+-------------------+-------------------+
|USER_ID |ADDRESS_ID| ORDER DATE |second_recent_order
+-----------+----------+-------------------+-------------------+
| 100| 1000 |2021-01-02 |2021-01-04
| 100| 1000 |2021-01-14 |2021-01-04
| 100| 1000 |2021-01-03 |2021-01-04
| 100| 1000 |2021-01-04 |2021-01-04
| 101| 2000 |2020-05-07 |2020-05-07
| 101| 2000 |2021-04-14 |2020-05-07
+-----------+----------+-------------------+-------------------