我有一些疑惑,不太明白为什么在线版本的λ-return算法需要在每次时间步长中都重新访问一个回合上所有时间步骤。这个问题来自以下书籍的第12章《强化学习导论》(第2版)作者是 Sutton & Barto:
Reinforcement Learning: An Introduction, 2nd Edition, Chapter 12, Sutton & Barto
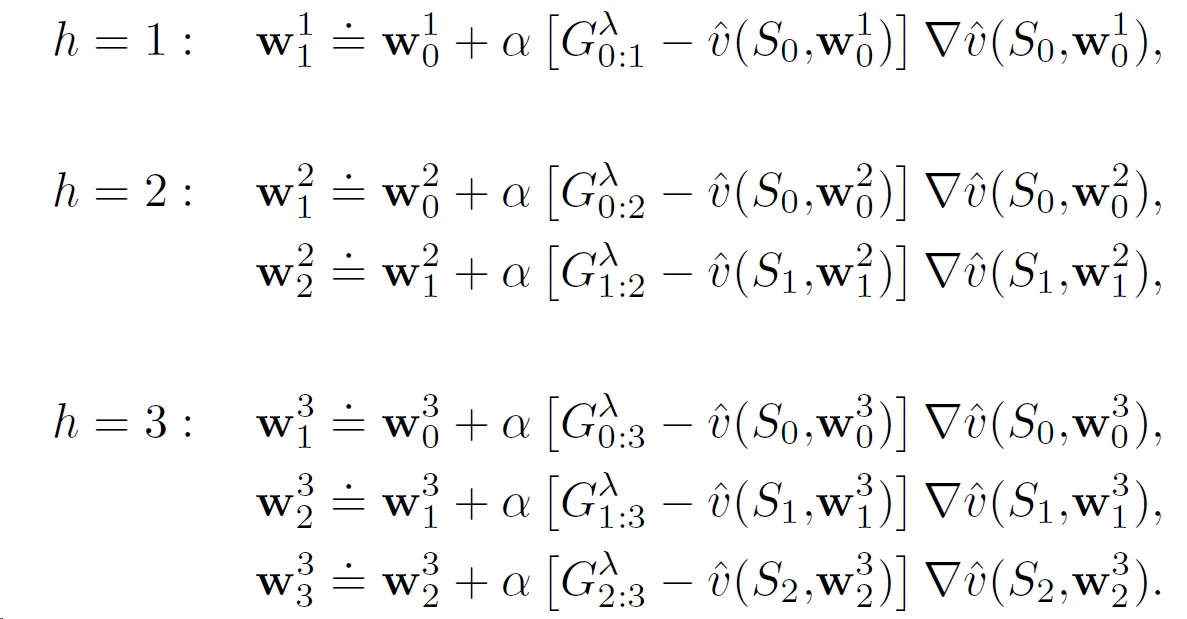
图中,每个时域 h 的权重向量序列 W1、W2、......、Wh 都从前一个回合结束时的权重 W0 开始。但它们似乎不依赖于先前时域的回报/权重,并且可以独立计算。这对我来说似乎只是为了澄清而解释,您只需在回合终止时为最终时域 h=T 计算即可。这与离线版本算法所做的相同,实际更新规则如下:
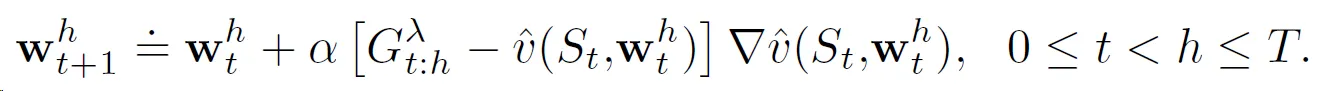
毫不奇怪,在19状态随机行走示例上,两种算法给出了完全相同的结果:
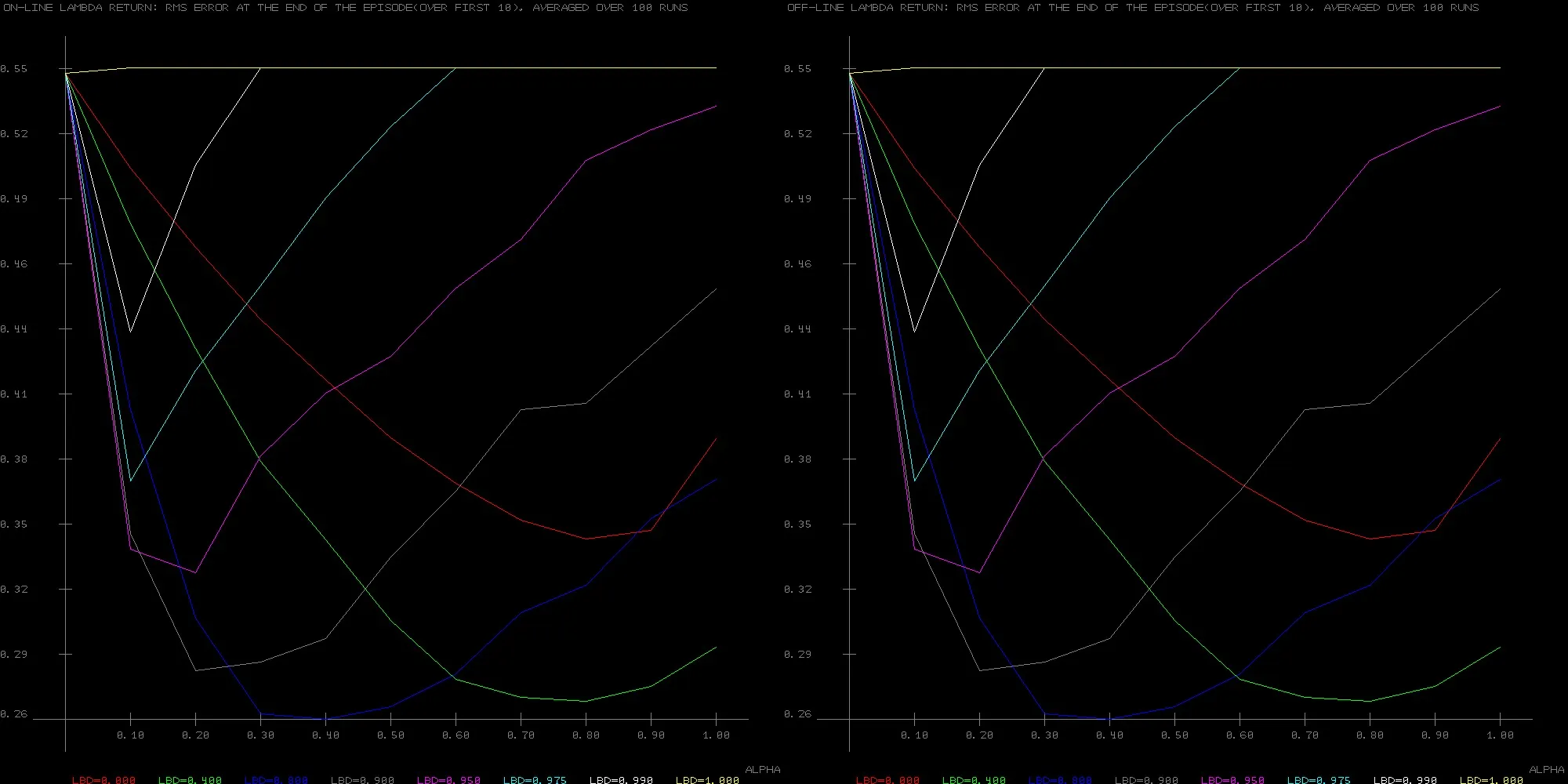
书中提到,在线版本应该表现得更好,并且在这种情况下应该与 True Online TD(λ) 的结果相同。但是,在实现后者时,其性能真的比离线版本要好得多,但是我无法想象简单而缓慢的在线版本为什么能做到这一点。
非常感谢您的建议。